TL;DR
GPT和PaLM等大型语言模型(LLM)能准确地理解自然语言指令并生成准确、富有创意的文本响应,可以作为编程助手、通用聊天机器人等新型应用的强力底座。但这些强大的模型依赖庞大的计算和高昂的运行成本,实际部署时对请求并发量和资源利用效率提出了关键性的挑战。伯克利大学研究人员受虚拟内存系统中分页(paging)技术启发,设计了PagedAttention,通过对显存的分块管理,实现了自注意力机制(self attention mechanism)中KV缓存的几乎零显存浪费和灵活的资源共享(如下图),并结合张量并行(tensor parallel)技术提高显卡设备计算核心的利用率,极大地加速了模型推理速度。与其他SOTA部署方案相比,提高了2~4x的吞吐量^1。
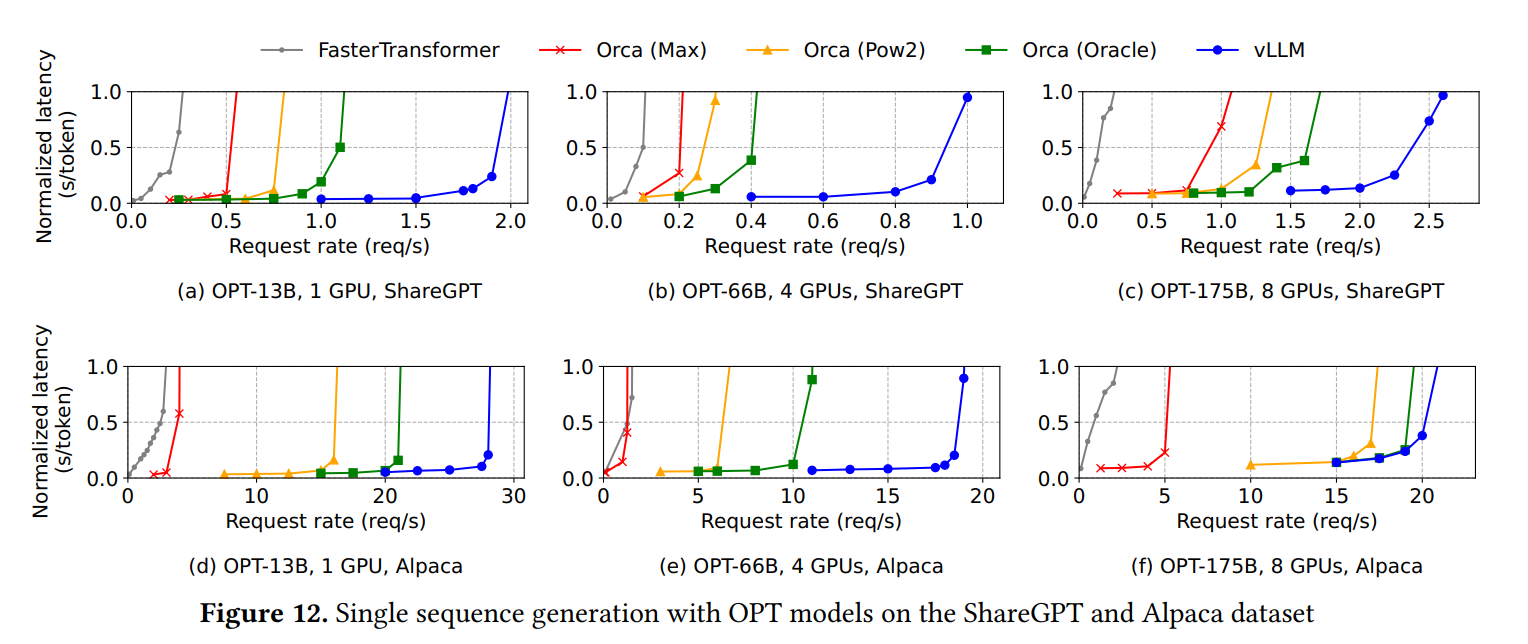
上效果图感受一下vLLM的加速效果,图中曲线颜色表示不同框架,蓝线是vLLM,横轴表示每秒请求数量(req/s),纵轴是延迟量化指标,即平均每个token生成时长(s/token)。可以看到vLLM可以在更高的并发请求量下保持推理速度,表示用户可以在更短的时间内获得他们的请求响应,从而提高了用户体验。
全局视角:vLLM的整体架构
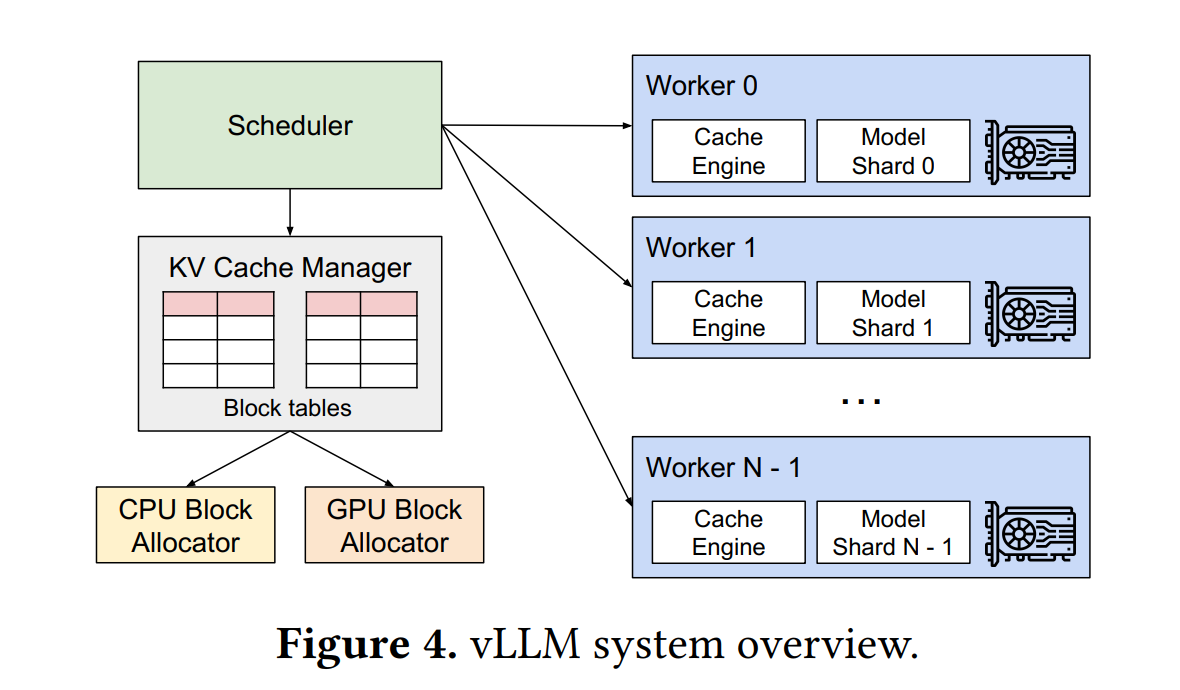
上图是一个LLMEngine实例的整体架构图,包含调度器(Scheduler)、缓存管理器(KV Cache Manager)、负载实例(Worker)几个主要部件:
- 调度器是vLLM的中央组件,根据资源分配情况更改请求(Request)状态,并通过调取缓存管理器得到数据复制(copy,指将源缓存块的数据完全复制到目标缓存块)、数据加载(swap,指内存与显存之间的数据交换)操作指令,从而提供计算所需的物理块信息。
- 缓存管理器构建了内存和显存的物理块(Physical Block)标识,提供了分配(allocate)、载入(swap_in)、载出(swap_out)、追加(append_slot)、派生(fork)、释放(free)等多个接口供调度器调用,实现缓存的动态分配。
- 负载实例负责执行大语言模型的计算,每个实例对应一张显卡设备,可以调取相应的存储和计算资源。
- 采用张量并行技术,即每张显卡设备上只保存一部分模型参数,称模型分片(Model Shard)。
- 除模型占用的显存外,其余显存以物理块为基本单元与缓存管理器的物理块标识一一对应,缓存引擎(Cache Engine)接收来自调度器的操作指令,实现对KV缓存的加载、拷贝操作。
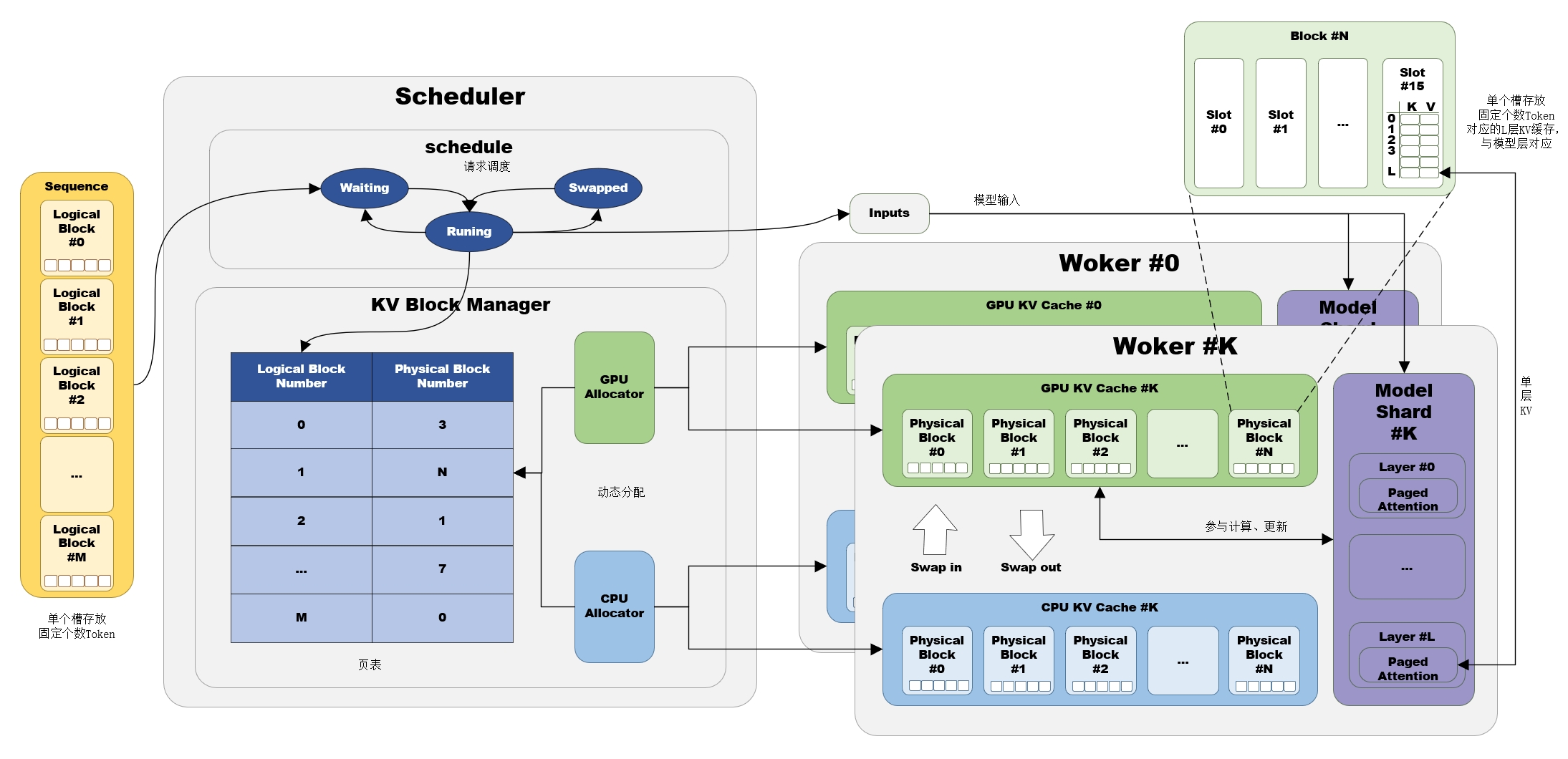
缓存分页:提高显卡存储利用率
背景:张量连续性导致的显存碎片化和过度预留
Transformer架构的生成模型在计算第个token的向量表征时,其内部的自注意力机制首先计算该token对应的Query、Key、Value向量,也即,然后与前文的分别计算注意力权重,并经Softmax函数归一化后,通过对前文的加权求和得到:
可以看到生成第个token要用到前个token的KV表征和,而且这些表征只受上文内容影响,对下文来说是静态的,那么为了避免每个token生成时对前文KV表征的重复计算,一般将这部分作为临时张量保存在显存中,用存储代价换取计算效率,从而节省生成时间。下图展示了13B模型在NVIDIA A100设备上运行时的显存分配情况,可以看到KV缓存占用超过了30%。
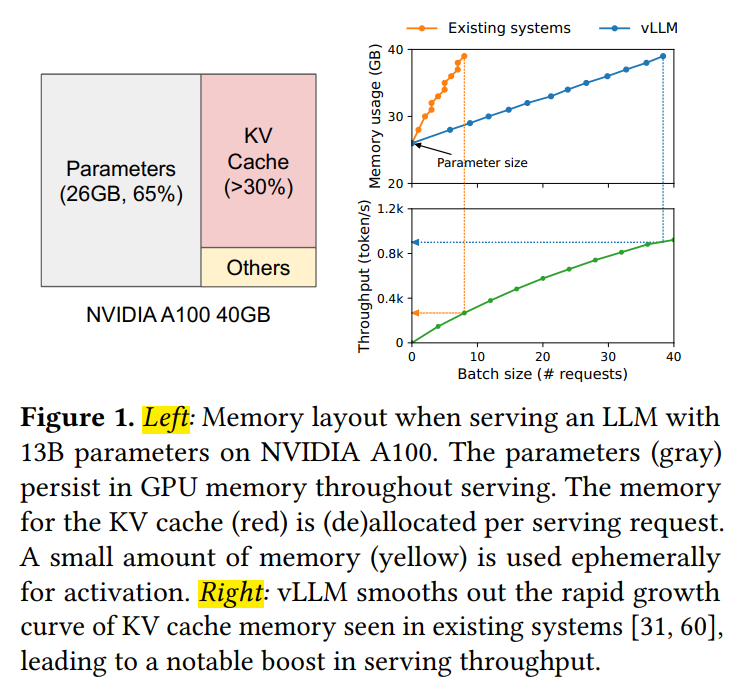
KV缓存常见的做法是将所有向量拼接成一个大的张量,这样在计算注意力权重时可以直接进行矩阵运算,但这也要求张量占用的显存空间是连续的。而文本生成场景下序列长度是动态变化的,也即张量尺寸是动态变化的,就需要频繁地创建和销毁张量,这不仅产生了额外的时间开销,还导致产生了大量碎片化显存空间,而这些空间后续无法被有效利用。另外,文本生成的长度是未知的,某些系统选择预留模型最大生成长度(如2048)所需的显存空间,这就导致文本较短时产生显存的过度预留,文中称内部碎片(Internal Fragmentation)。过度预留还发生在批次化计算多个长度不同的序列的情况,此时一般用补0的方式(padding)将不同序列的张量长度对齐,导致不必要的浪费,文中称为外部碎片(External Fragmentation)。以上三点是导致显存资源没有被有效利用的最大问题。
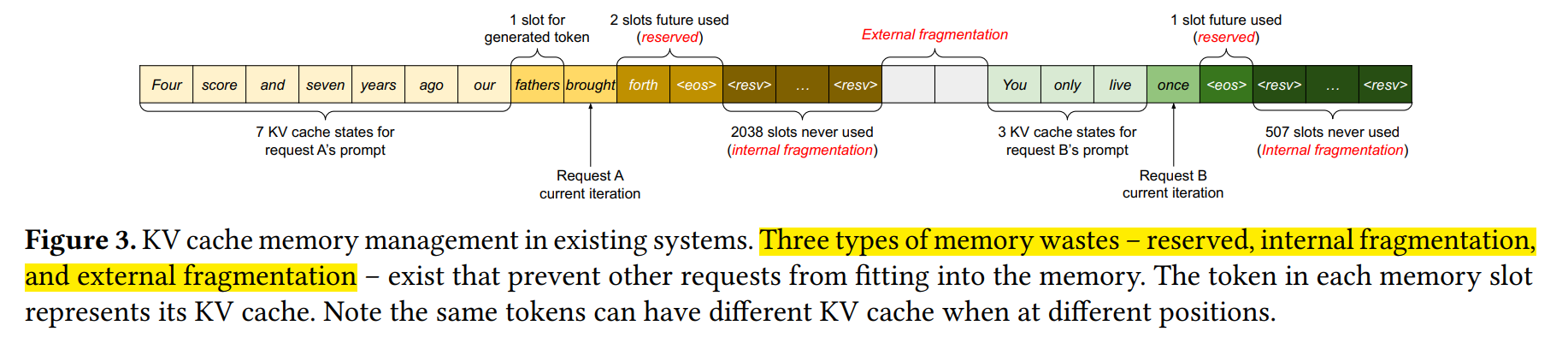
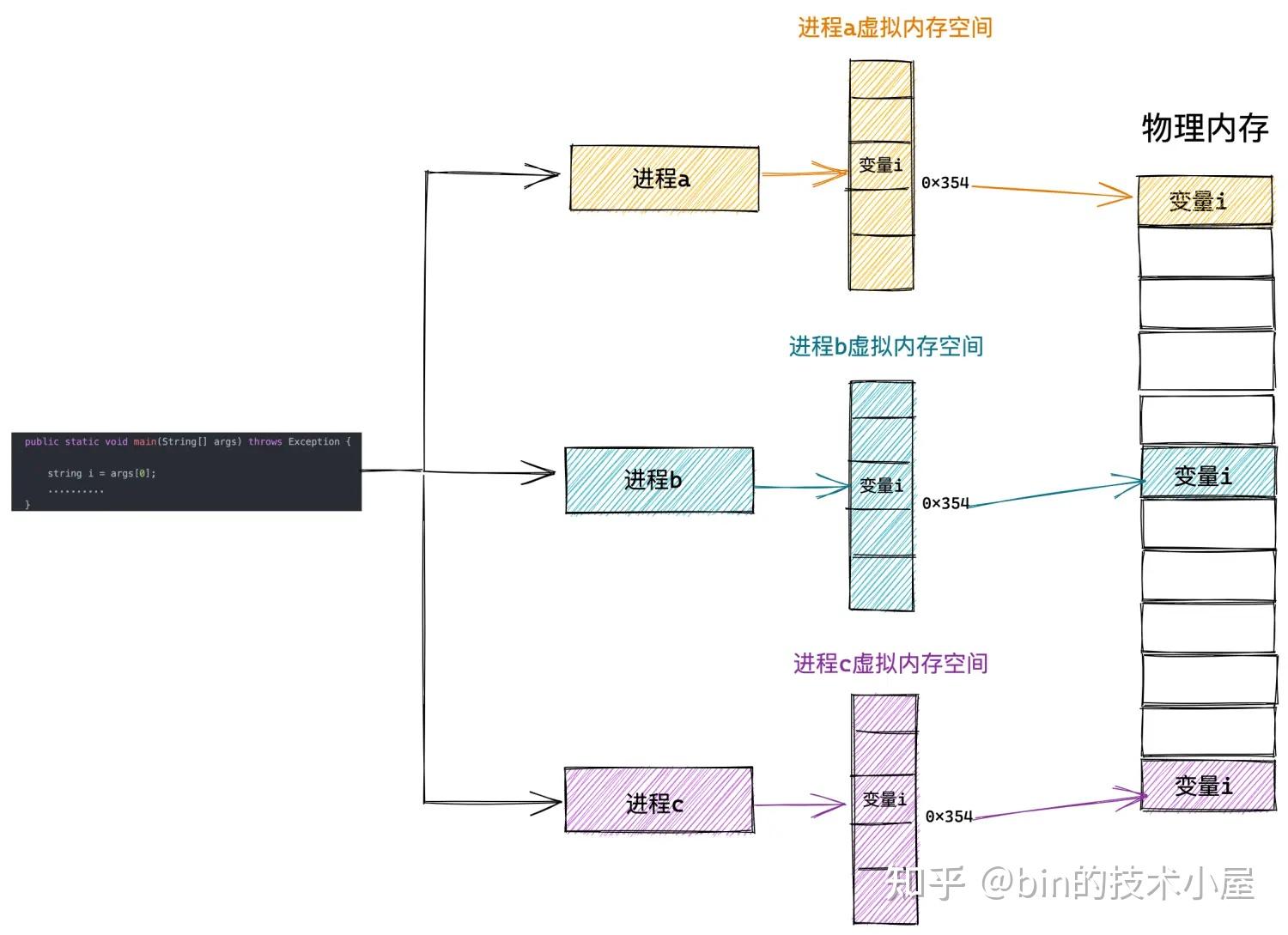
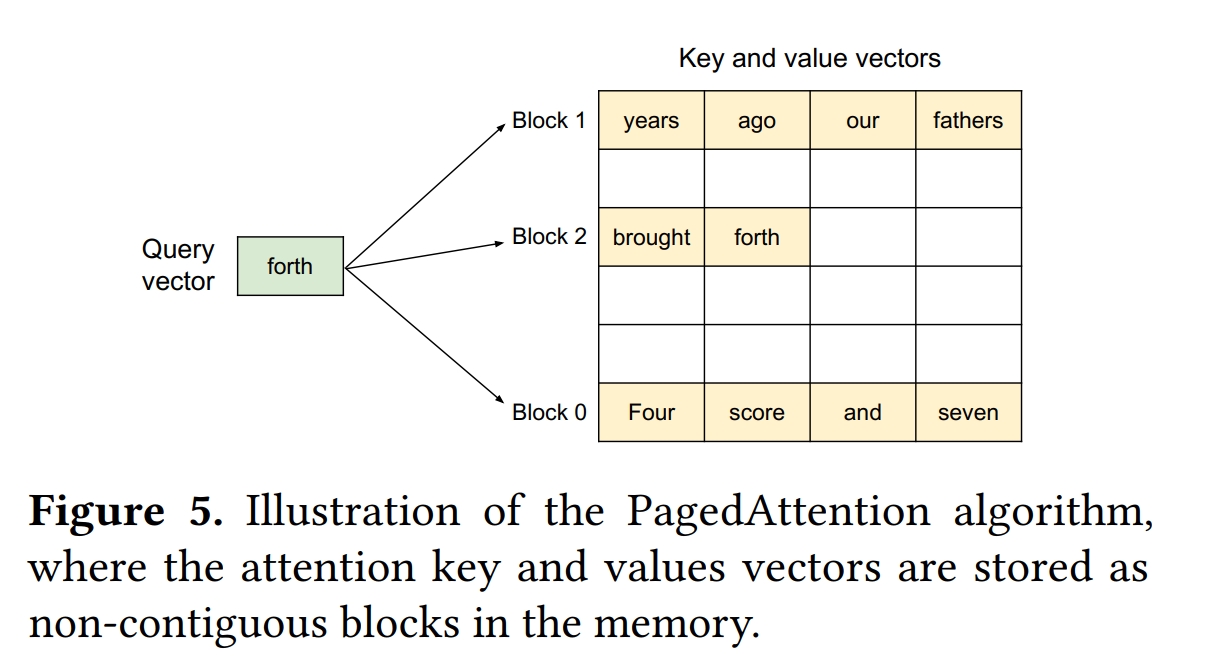
那么vLLM是怎么解决这些问题的呢?实际上,显存碎片化和过度预留的根本原因,是对缓存空间的连续性要求,那么首要问题就是解决KV缓存的离散存储与计算调用问题。受操作系统虚拟内存与分页的启发,vLLM提出了PagedAttention,通过引入分页机制管理KV缓存,实现更灵活、高效的显存管理。具体地,是将KV缓存划分为多个块(或称为页),每个块包含了固定数量的Token对应KV张量。那么KV缓存可以存储在离散的内存空间中,可以用更灵活的方式进行管理。如果用操作系统的虚拟内存系统进行类比,那么块(Block)相当于页(Page)、Token相当于字节(Byte)、请求(Request)相当于进程(Process),如下图。这种设计可以实现:
- 几乎零显存浪费:块是随着序列增长动态申请的,显存预留只发生在最后一个块,而且不同序列的KV缓存也无需填充来对齐,减少了不必要的显存浪费,提高了显存的有效利用率;
- 灵活的资源共享:在束集搜索(Beam Search)或采样等多序列生成过程中,输入的Token序列可以在多序列间共享,进一步提高了显存资源的有效使用,并有助于提高系统的吞吐量。
内存池&显存池:KV缓存的离散存储
缓存空间的分页规划
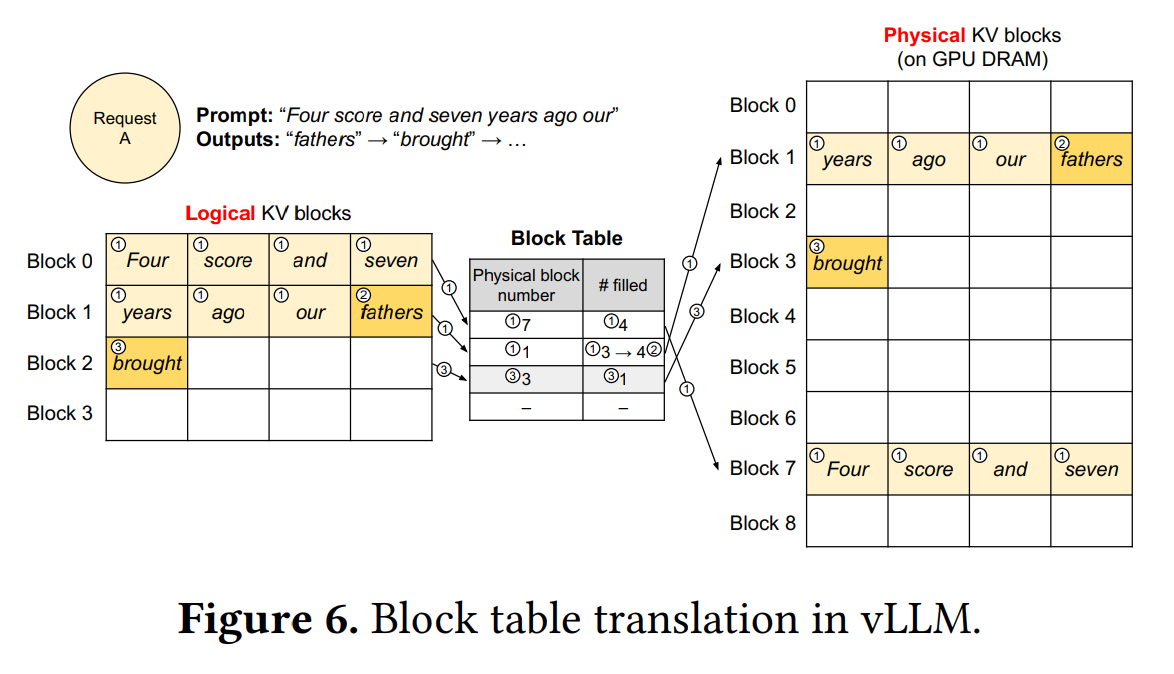
vLLM采用类似于操作系统的虚拟内存管理方式,将KV缓存划分为逻辑块和动态分配对应的物理块,实现内存和显存缓存空间的高效规划。逻辑块和物理块的分离,使得vLLM能够动态分配KV缓存空间,而不需要提前为所有位置预留缓存。这种分页机制允许动态增长KV缓存内存,无需提前保留所有内存,从而减少了内存浪费,特别适用于文本生成场景下的动态长度序列,有效提高了系统的性能和资源利用率。
逻辑块与物理块:逻辑块(Logical Block)的概念类似虚拟内存中的逻辑页,用于组织和管理Token序列。Token序列被分块存储在多个连续编号的逻辑块中,每个逻辑块具有固定数量的槽(Slot),并按照先后顺序存放Token,未填充的槽预留给将来生成的Token。物理块(Physical Block)类似虚拟内存中的物理页,是vLLM的缓存管理单元,是开辟在CPU内存或GPU显存中的连续存储区域,分为CPU物理块和GPU物理块,用于存储Token序列对应的KV缓存。每个物理块对应一个逻辑块,也具有与逻辑块相同的槽位数量,物理块的槽存储了对应Token的KV缓存张量。
物理块的唯一标识:缓存空间经初始化后作为成员变量保存在工作负载的缓存引擎(Cache Engine)中,等待缓存管理器(KV Cache Manager)进行申请、释放等操作。缓存管理器初始化时,为每个物理块(包括CPU、GPU存储)构建PhysicalTokenBlock实例,定义了block_number作为物理块的唯一标识,用于记录每个物理块在缓存中的位置或索引,以便在后续的操作中可以通过block_number来识别和操作特定的物理块。这个标识在分配、释放和管理物理块时非常重要,因为它允许系统跟踪和操作不同物理块的状态和位置,确保正确地分配和回收内存资源。
页表(内存映射):逻辑块是根据Token位置连续编号的,但物理块是动态分配的,block_number不一定连续,缓存管理器中维护了一个页表,来记录逻辑块和物理块之间的映射关系,用于追踪哪些逻辑块被分配到了物理块上。具体实现时,由于逻辑块已是有序的,因此只需将每个逻辑块对应的物理块依次存放在有序列表中即可。
序列的分块存储:Token序列被分割成多个逻辑块,这些逻辑块按照先后顺序存放Token。与Token序列相对应,KV缓存被组织成多个物理块,每个物理块具有与逻辑块相同数量的槽,存储逻辑块中的Token对应的KV缓存张量,确保正确关联的注意力KV缓存。逻辑块和物理块之间的关系通过页表(内存映射)来维护,逻辑块编号与分配给它的物理块编号一一对应,使系统能够知道每个逻辑块的KV缓存张量存储在哪个物理块中,从而有效检索和管理这些缓存数据。
块尺寸的大小选择:块尺寸即逻辑块或物理块中的槽位数量,较大的块尺寸允许PagedAttention在更多的Token上并行处理KV缓存,从而提高硬件利用率、降低延迟,但是较大的块尺寸也会导致内存碎片化现象,导致性能下降。因此块尺寸的设置对系统性能和内存利用率影响较大。在实际性能评估中,一些工作负载在设置较大的块尺寸(从16到128)表现最佳,而另一些工作负载中较小的块尺寸(16和32)更有效,具体选择取决于序列长度和工作负载的特性。vLLM默认将块尺寸设置为16,以在绝大多数工作负载下实现良好的性能和内存管理的平衡。
缓存空间的动态调取
经过上述对缓存空间的规划后,接下来的问题是,应该如何动态分配块并读取块中的数据?vLLM将缓存空间的动态调取封装成了缓存管理器(KV Cache Manager),实现存储资源的动态分配。
块操作:缓存管理器负责维护页表,以记录逻辑块与物理块之间的映射关系,还负责管理块的分配、释放和加载等。其提供了一系列接口供调度器调用,实现缓存块的分配、释放等操作。缓存管理器提供的接口如下:
- allocate(分配): 该接口用于分配新的物理块,以存储KV缓存数据。在分配时,它考虑了可用内存资源,并根据需要分配CPU内存或GPU显存的块。
- swap_in(载入): 当KV缓存需要从CPU内存载入到GPU显存时,该接口用于执行载入操作。它会将数据从CPU块复制到GPU块,并维护相应的块映射关系。
- swap_out(载出): 用于将KV缓存从GPU显存移到CPU内存的接口。它同样执行块之间的数据复制操作,并维护块映射关系。
- append_slot(追加): 当需要追加新的Token时,该接口用于分配块,以便将新Token添加到合适的逻辑块和物理块中。
- fork(派生): 当需要创建一个与现有序列共享物理存储的新序列时,该接口用于派生块,并通过共享机制确保多个序列共享相同的物理块。
- free(释放): 用于释放不再需要的物理块,以便将资源回收并可用于其他序列。
- reset(重置): 在需要清除所有映射和释放所有资源时,该接口用于将管理器重置到初始状态。
此外,缓存管理器还提供了有关可用内存块数量的查询接口,以便在决策如何分配和释放内存资源时提供有关内存使用情况的信息。
块的动态分配:vLLM动态地为逻辑块分配新的物理块,只有在所有先前的块都已满时才会分配新的物理块。缓存空间的预留只会发生在最后一个块中,因此可以实现几乎零缓存空间浪费。一旦请求完成生成,这些块会被释放,并由其他请求进行分配。
下图展示了一个序列生成过程中的分块存储与动态分配过程(块尺寸为4)。输入Prompt共7个Token,首先将其顺序存放在逻辑块#0和逻辑块#1中,通过调用allocate接口一次申请所需的物理块,即物理块#7和物理块#1,并通过页表建立逻辑块到物理块的映射。当输出第一个Token后,调取append_slot追加新生成的Token。此时逻辑块#1还存在空缺,因此将其追加到逻辑块#1的槽位#3中,相应地,在下次计算时将KV缓存存放在物理块#1的槽位#3。输出第二个Token时,同样调取append_slot,此时所有已申请的块已满,因此申请新的存储空间,即逻辑块#2和动态分配的物理块#3,在逻辑块#2的第一个槽位写入生成的Token,在下次计算时在物理块#3的第一个槽位写入KV缓存。
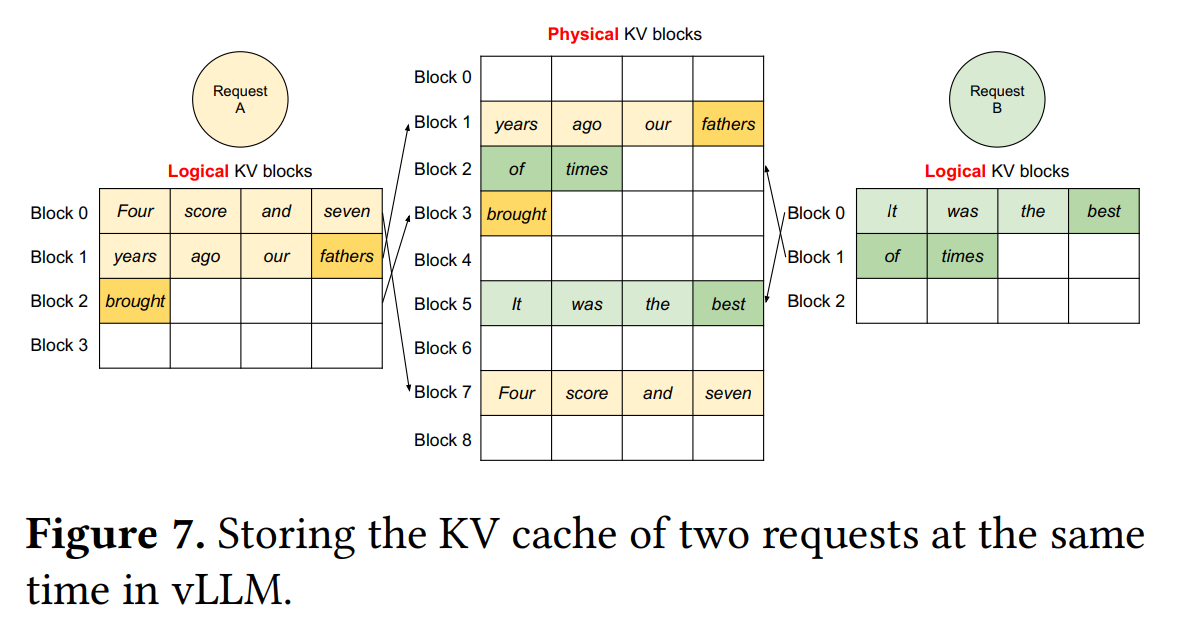
该机制同样适用于多请求的批处理,如下图。
块数据的复制与加载:以上动态分配的过程发生在在调度阶段,实际上,缓存管理器主要负责修改物理块的状态,例如是否已占用以及引用计数等,但并没有直接操作物理块的数据内容。块数据的复制与加载操作在执行阶段由负载实例(Worker)来执行。这一过程发生在执行模型计算之前,通过调用缓存引擎(Cache Engine)来实现。vLLM编写了底层CUDA kernel实现数据复制和加载:
csrc/cache_kernels.cu::swap_blocks:在不同设备之间交换块数据,实现块数据的设备切换。用于低优先级请求发生阻塞时临时释放显存空间,或者重新恢复被阻塞的请求(见下文「请求调度避免显存占用溢出」)。首先确定源张量和目标张量的设备类型,并根据设备类型选择相应的内存拷贝方式。然后通过block_mapping中的映射关系,在异步CUDA流中进行数据拷贝,将源块中的数据复制到目标块。csrc/cache_kernels.cu::copy_blocks:用于在执行块数据的复制。是在写时复制(Copy on Write,见下文「多序列缓存资源共享」)。将输入的KV缓存张量的指针信息整理成数组,根据源物理块地址和目标物理块地址创建地址映射数组。然后将执行数据复制。
块数据的读写和计算:当完成所有数据复制和加载操作后,模型才执行相应的计算。注意到,KV缓存只参与了各层注意力机制的运算,vLLM实现了在PagedAttention,通过页表精确定位所需访问的物理块,并访问读取存储在这些物理块中的键值缓存(KV缓存),然后用不连续块存储的KV张量执行注意力机制运算,如下图所示。计算完成后,将新生成下一个Token的KV缓存追加到页表指定的物理块中(该块的分配已在调度阶段完成,详情见后文)。
(CPU物理块和GPU物理块之间的交换加载)
多序列缓存资源共享
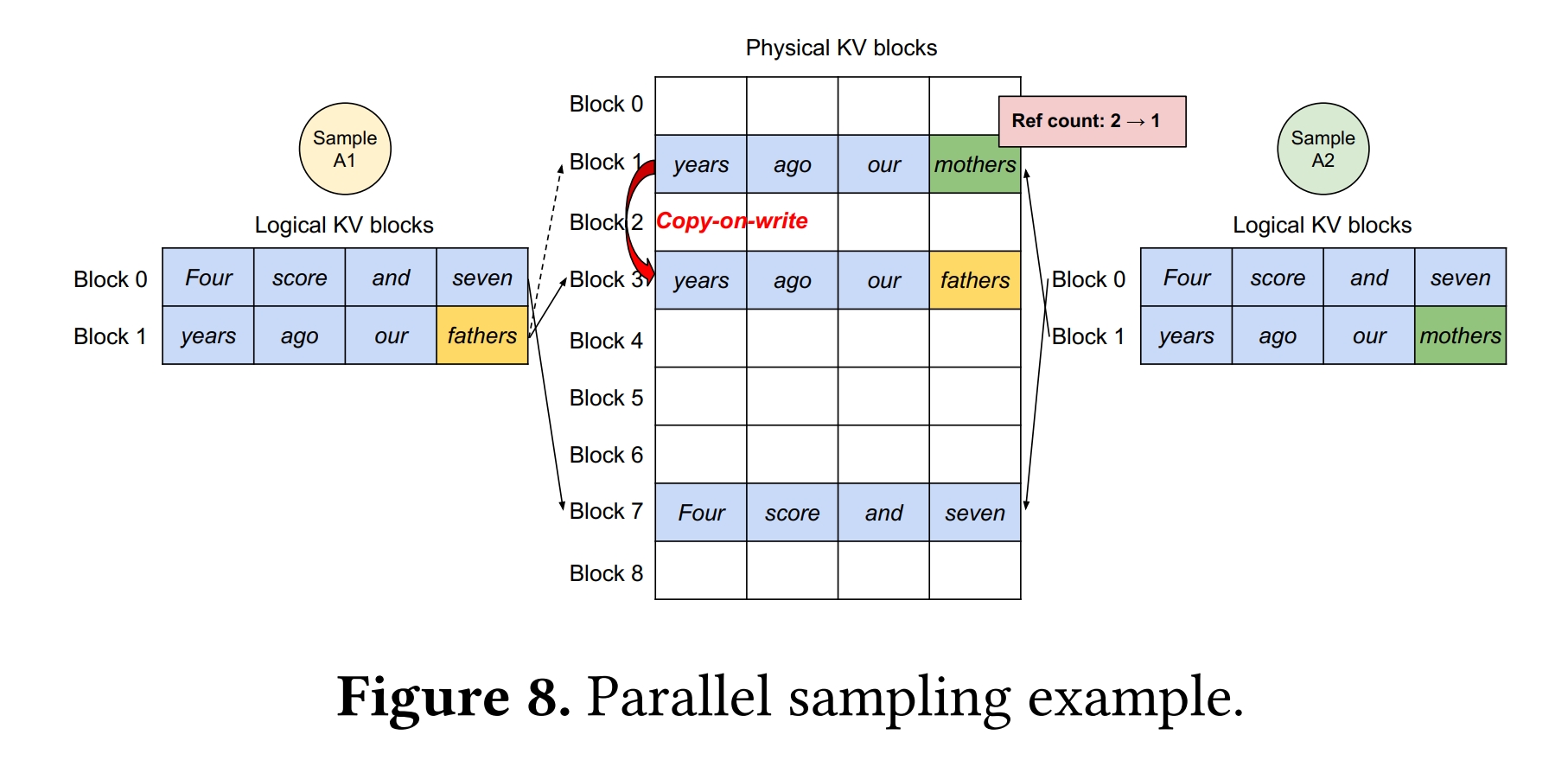
实际上,当多个序列共享相同的Prompt时(如并行采样生成多个响应),Prompt部分的KV缓存也完全一致,因此为每个序列单独分配缓存空间是极大的浪费。vLLM 在非连续空间中存储KV缓存的特性,允许这些序列读取到相同物理块的缓存数据,实现序列间共享缓存资源,从而节省宝贵的缓存空间。与虚拟内存类似,vLLM也采用引用计数和写时复制实现资源共享。
引用计数(ref_count):每个物理块(PhysicalTokenBlock)都有一个引用计数,用于跟踪有多少个序列共享该物理块的内存。引用计数的目的是确保当多个序列共享同一块内存时,只有在最后一个序列不再需要该块内存时,才会将该块内存释放。这可以防止内存泄漏和重复释放的问题。
写时复制(copy on write):当多个序列需要修改同一块内存时,为了避免冲突和数据不一致,vLLM实现了写时复制机制。写时复制意味着在需要修改内存的情况下,首先检查该内存块的引用计数。如果引用计数大于1,说明有多个序列共享该内存块,此时会进行复制操作,创建一个新的物理块,将原始块的内容复制到新块中,然后修改新块。同时,原始块的引用计数会减少,以表示它不再被多个序列共享。这样,不同序列之间的修改不会相互影响,保持了内存的数据一致性。
实例说明:如图8所示,有两个共享相同Prompt的序列 A1 和 A2,并且在生成阶段需要分别修改自己的KV缓存。两个序列的逻辑块 #0 和 #1 分别映射到物理块 #7 和 #1 。开始时,物理块 #7 和 #1 的引用计数都为2,表示它们被两个序列共享。当序列 A1 需要写入其最后的逻辑块(逻辑块 #1)时,vLLM检测到物理块 #1 的引用计数大于 1 ,于是它分配一个新的物理块(物理块 #3),要求块引擎将信息从物理块 #1 复制到新的物理块 #3,并将物理块 #1 的引用计数减少到 1。接下来,当序列 A2 需要写入物理块 #1 时,由于物理块 #1 的引用计数已经减少到 1 ,所以 A2 可以直接将其新生成的 KV 缓存写入物理块 #1。通过这种方式,vLLM允许在多个输出样本之间共享大部分用于存储Prompt的KV缓存的空间,只有最后一个逻辑块需要通过写时复制机制来管理。通过共享物理块,可以大大减少内存使用,特别是对于长输入Prompt的情况。
请求调度:避免显存占用溢出
生成类应用往往面临这样的问题:用户的输入Prompt的长度各异,而生成的输出也无法提前预知(取决于输入提示和模型的组合)。当请求数量增加,或随着输出序列的增长,缓存空间的需求量也相应地增加,可能导致系统内存不足和显存溢出。为了解决这个问题,vLLM引入调度器(Scheduler)来管理和调度请求和计算资源,决定请求的优先级和资源分配策略,以确保请求的有序处理,从而确保系统在高负载情况下能够稳定运行。
请求优先级与调度:当请求超出系统可处理的容量时,vLLM设计了调度策略来分配有限的计算资源。具体地,vLLM采用先到先服务(FCFS)调度策略来管理请求,根据请求的到达时间设定优先级,越早收到的请求处理优先级越高,确保最早到达的请求首先得到服务,防止请求等待过久。当系统资源不足时,暂时阻塞低优先级请求并回收其占用的缓存空间,然后用这些临时空间继续处理高优先级请求。当高优先级请求处理完毕,再将资源分配给低优先级请求,这样依次完成,确保各个请求都能得到足够的计算资源。
![]()
请求的三态转移:调度器通过修改请求的状态来实现阻塞或者恢复运算等。请求状态共有三种,分别是等待(WAITING)、运行中(RUNNING)、和已交换(SWAPPED):
- 等待(WAITING):当请求首次到达系统时,它被置于WAITING状态。调度器根据调度策略和系统资源情况,将WAITING状态的请求转移到RUNNING状态。注意,当发生抢占操作时,不会将WAITING状态切换到其他状态,确保不超出系统的资源容量。
- 运行(RUNNING):当系统资源允许时,调度器将请求从SWAPPED或WAITING状态切换到RUNNING状态。注意,系统优先切换SWAPPED状态请求为RUNNING,WAITING需等待全部SWAPPED请求完成后,再进行切换。RUNNING状态下的请求将获得缓存资源和计算资源并执行计算。调度器会根据系统资源情况决定是否将RUNNING状态的请求切换到SWAPPED状态。
- 已交换(SWAPPED):即阻塞请求,当系统资源不足时,调度器会阻塞低优先级的请求,视情况将状态切换到SWAPPED状态(preempt by swap)或WAITING状态(preempt by recompute),并暂时释放其占用的缓存空间。以上两种被阻塞的请求分别用以下两种方式进行恢复:Swapping(交换)和Recomputation(重新计算)。
- Swapping(交换):当内存不足时,调度器可以将低优先级请求的数据块从GPU内存换出到CPU内存,以腾出GPU内存供高优先级请求使用。一旦高优先级请求完成,低优先级请求的数据块可以被换回GPU内存。值得注意的是,换到CPU物理块的数量永远不会超过GPU物理块的数量,也就是说CPU交换空间受限于GPU显存大小。
- Recomputation(重新计算):如果资源允许,调度器可以选择重新计算低优先级请求的数据,而不是将其交换到CPU内存。这可以降低性能开销,因为重新计算通常比数据交换更快。
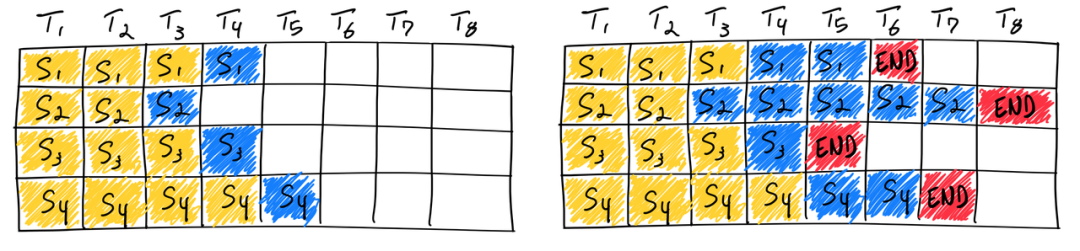
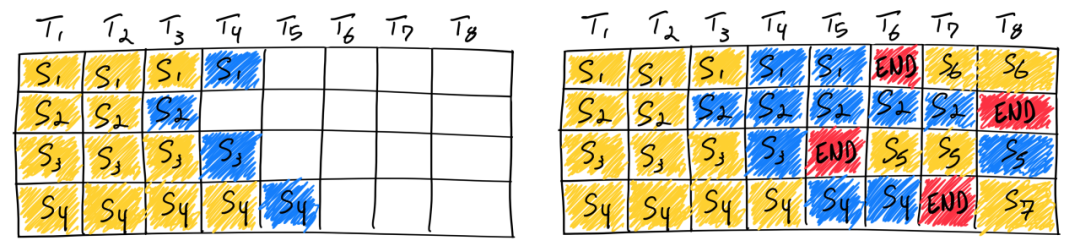
补充说明一点,vLLM框架通过这种调度方案实现了连续批处理(Continuous Batching)。上图第一行展示的是常见的静态批处理(Static Batching),即批大小在推理完成之前保持不变,🤗transformers采用的就是这种。可以看到,同一批次内的不同序列具有不同的长度,那么完成解码的顺序必然存在先后,而静态批处理意味着必须等待全部序列完成解码,即解码时长由最长序列决定,这显然是低效的。连续批处理不同,批次大小是每次迭代开始前确定的,比如vLLM在迭代开始前通过调度器实现序列的调度和加载。那么先完成的序列就可以提前退出,并将资源释放给等待或阻塞的序列使用。
张量并行:提高显卡计算核心利用率
大语言模型(LLM)的参数规模一般超出单个显卡的显存容量,因此多卡分布式计算是必要的。vLLM采用了与Megatron-LM相同的张量并行(Tensor Parallel)策略^2,基于矩阵分块运算将模型分片后分配到不同的显卡设备,执行单个网络层的张量计算时每个设备负责其中一部分,这样多卡可以同时计算,最大化地利用了分布式系统的计算资源。
原理:Embedding、Linear、Attention的并行化
张量并行的关键在于实现模型的分片,将存储和计算均衡地分配到各个显卡设备上。Transformer架构的模型中带参数的网络模型有嵌入层(Embedding)、线性层(Linear)和注意力层(Attention),这三种层的结构差别很大,需要定制化地进行设计。
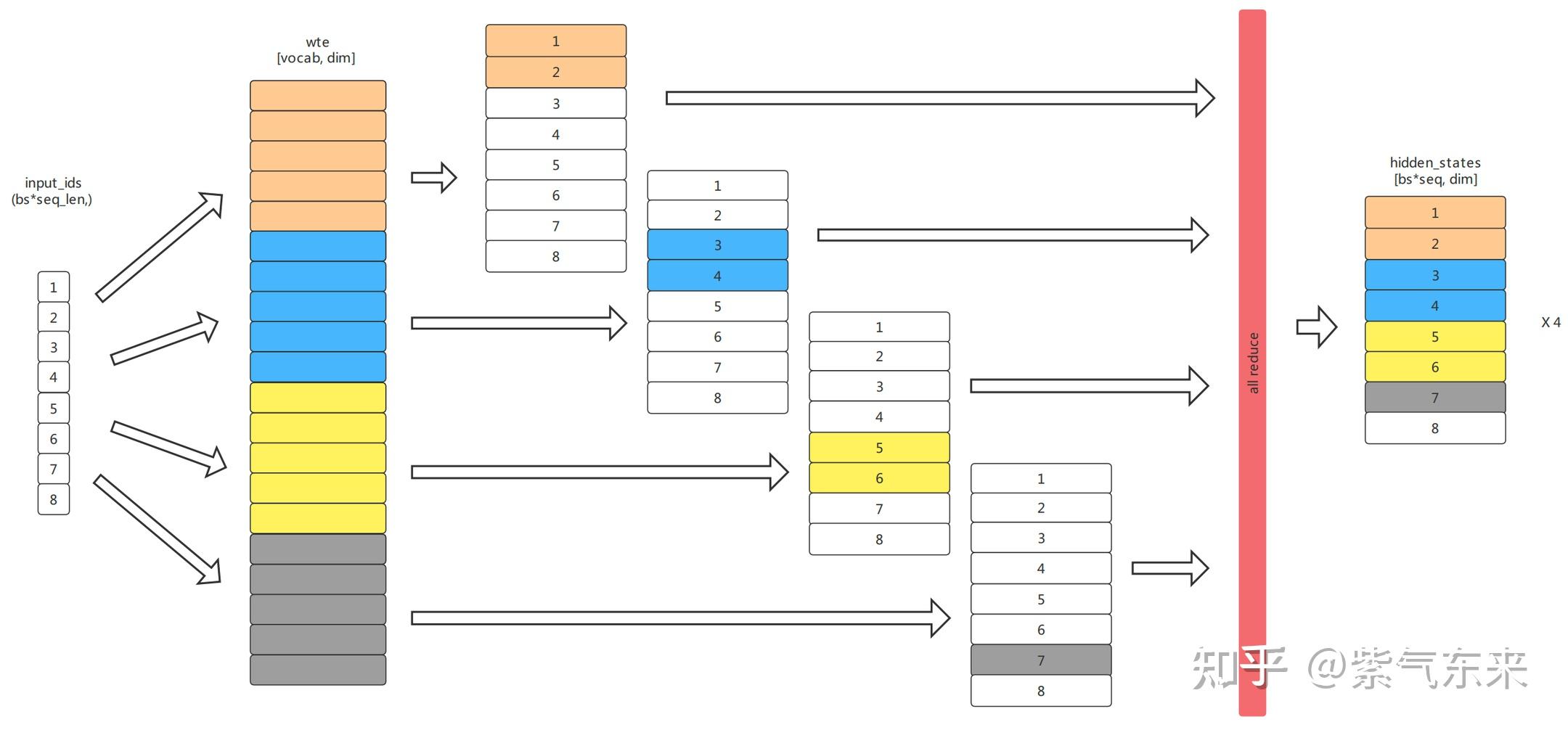
嵌入层(Embedding):Transformer模型的嵌入层负责将输入的 Token 序列映射为对应的词向量。并行化嵌入层的关键在于将词汇表(vocabulary)分配到不同的显卡设备,每个显卡设备只负责处理一部分词汇表,实现并行计算。主要涉及到权重分片、输入数据复制、独立查表以及全局归约(All-reduce)。具体地,首先将权重矩阵分割成多个部分,每个部分存储在不同的显卡上。执行计算时,先将输入数据复制到所有显卡上,然每张显卡分别使用对应的权重部分来执行查表操作,将输入 Token 序列映射为嵌入向量。最后执行全局归约操作(All-reduce),合并不同显卡上的计算结果得到最终的嵌入向量。
上图来自「Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism」
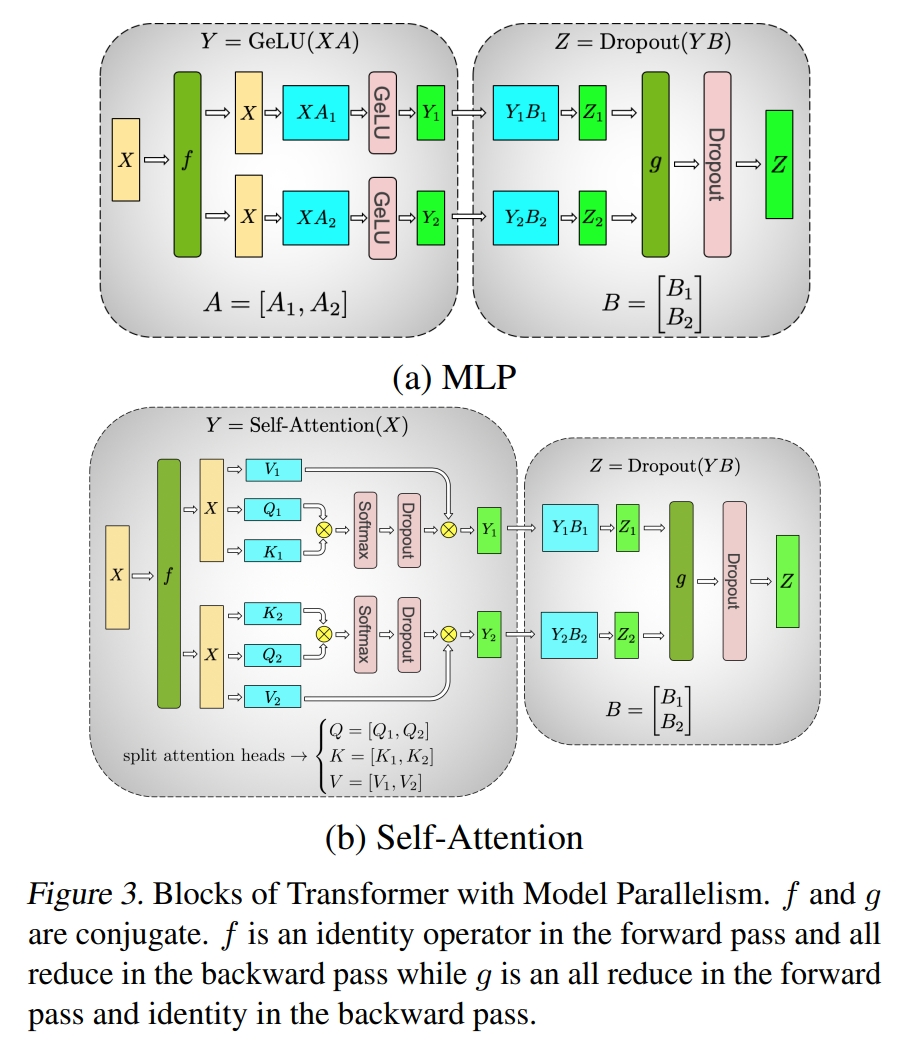
线性层(Linear):线性层是构建神经网络模型最主要的网络类型,网络权重主要集中在线性层。线性层的运算可以表示为,其中是输入、是权重参数、是输出,可以有列并行、行并行两种并行策略。列并行是将权重矩阵按列划分,得到,根据矩阵分块原理,计算结果是。行并行是将权重矩阵按行划分,得到,计算结果是。注意到,列并行层输出的结果可以不经过设备间的数据交换,就能立即送入行并行的计算,而Transformer采用了Bottleneck设计,包含两个线性层,先用一个线性层将输入的词向量投影到高维空间(一般维数扩张4倍),然后经激活函数的非线性操作,再用另一个线性层执行降维,从高维空间投影回词向量空间。因此,为了保证各显卡设备上的计算相互独立、减少通讯量,Transformer采用列并行加行并行的方式,对Bottleneck进行并行化处理,也就是将第一层权重按列分片为,将第二层权重按行分片为,第张显卡设备负责和分片。并行最终结果用下式计算得到:
注意力层(Attention):注意力层的并行可以充分利用多头注意力的天然并行性。首先将Key、Query、Value相关权重合并,即,然后进行列并行分片,得到,这样每个分片自然地负责了若干注意力头的计算,由于各注意力头的计算是独立的,不需要通讯就能完成分片的注意力计算。注意力之后的线性层采用行并行。
KV缓存的并行化
模型并行化后,KV缓存也相应地需要并行化处理。vLLM的多个工作负载(Worker)共享一个缓存管理器(KV Cache Manager),也就是说从逻辑块到物理块的映射(页表)也是共享的。这样,不同设备的相同编号的物理块存储的,是该设备上模型分片对应的KV缓存,换句话说,这个设备上的工作负载仅存储其对应的注意力头的KV缓存。在执行计算时,调度器首先将请求的Token序列和页表信息广播发送到各个工作负载,工作负载根据页表映射的物理块索引读取对应位置的KV缓存并执行计算即可。这个过程中,不同负载间的计算始终是独立的,只需要在计算开始时接收缓存信号(即页表)和输入序列即可,计算过程中不需要任何同步操作,降低了系统的复杂性。
讨论:适用场景
如上文所说,对语言生成这种与进程类似的、需要动态分配空间资源的应用,分页机制非常有效。但对于固定张量尺寸的应用(如图像生成),可能会产生额外的维护内存的花销。在这些情况下,引入vLLM的技术可能会增加内存管理和内存访问的额外开销,从而降低性能。
参考资料
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention - vllm.ai
- Efficient Memory Management for Large Language Model Serving with PagedAttention
- vllm-project/vllm - github
- vllm.readthedocs.io
- LLM 高速推理框架 vLLM 源代码分析 / vLLM Source Code Analysis - 知乎
- NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 - 知乎
- 一步一图带你构建 Linux 页表体系 —— 详解虚拟内存如何与物理内存进行映射 - 知乎
- DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED - pytorch.org
- torch分布式训练 - CSDN
- 分布式并行计算——张量并行 - 知乎
- NLP(六):GPT 的张量并行化(tensor parallelism)方案 - 知乎
- 【深度学习】【分布式训练】一文捋顺千亿模型训练技术:流水线并行、张量并行和3D并行
- How continuous batching enables 23x throughput in LLM inference while reducing p50 latency - anyscale
- Continuous Batching:一种提升 LLM 部署吞吐量的利器 - 幻方 x 深度求索
- How continuous batching enables 23x throughput in LLM inference while reducing p50 latency - Anyscale/Blog

