一、这是什么
video-knowledge-purify 技能,用于将视频内容自动转换为结构化的 Markdown 知识笔记。它的核心流程只有三步:转录 → 分段 → 汇总。
🔗 源码与使用说明:https://github.com/isLouisHsu/skills/tree/main/skills/video-knowledge-purify
你丢给它一个视频文件(或者已有 SRT 字幕),它会自动完成以下工作:
- 音频转录:把视频中的语音转为带时间戳的 SRT 字幕;
- 内容分段:调用文本 LLM 按语义主题切分字幕,识别知识点边界;
- 内容汇总:调用 VLM 结合字幕文本和视频关键帧,逐段生成 Markdown 笔记。
最终输出是一份可直接导入 Obsidian、Notion 或任何 Markdown 知识库的 note.md,每个段落都标注了时间范围,并配有对应的关键帧图片。
二、为什么需要这个 Skill
视频是高质量知识源,但消费和沉淀的成本极高。
-
视频不适合快速检索和复习。B站、YouTube、知识付费课程里有大量干货,但视频形态决定了你无法像搜索文档一样快速定位某个概念。看完就忘,三个月后想回顾某个知识点,只能凭印象拖动进度条。
-
内容密度低,整理耗时巨大。一个 30 分钟的技术分享,有效信息量可能只有几千字,但人必须花 30 分钟看完,再手动截图、记笔记、打时间戳。整套流程下来,时间成本翻倍,大多数人走到“转录出文字”这一步就放弃了。
-
现有转录工具止步于“一堆文字”。Whisper 能把视频转成 SRT,但得到的是未经组织的原始文本,没有分段、没有重点提炼、没有视觉辅助。直接把几万字的字幕丢进知识库,可读性几乎为零。
-
手动笔记容易半途而废。很多人硬盘里躺着几十个 G 的“稍后看”视频,但因为缺乏高效的整理工具,它们始终没有被转化为可检索的知识资产。
-
知识库需要结构化输入。Obsidian、Notion、Logseq 等工具的核心是 Markdown,而手动从视频生成 Markdown 的工序过于繁琐:要同步时间戳、要挑选关键帧、要提炼要点、要组织层级。
这个 Skill 要做的,就是把这套繁琐的流程自动化。 视频仍然是你的输入源,但最终沉淀下来的是一份结构清晰、图文并茂、可搜索的 Markdown 笔记。
三、如何使用
安装技能:
1 | npx skills add https://github.com/isLouisHsu/skills --skill video-knowledge-purify |
需要配置两段模型 API 密钥(均支持 OpenAI 格式)。推荐在 skill 目录下创建 .env 文件:
1 | cp .env.example .env |
配置示例(阿里云百炼):
1 | # 用于视频内容分段(文本 LLM,建议用便宜快速的模型,如 qwen-turbo) |
然后你就可以在Agent里输入/video_knowledge_purify 处理这个xxx.video使用了!
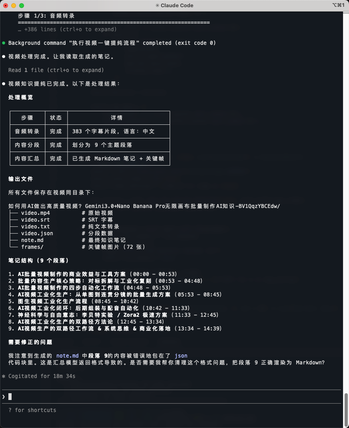
最终处理笔记如下:
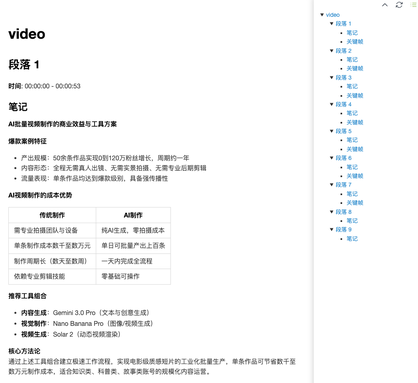
四、它默默做了哪些工作?
1. 音频转录:从视频到 SRT
transcribe.py 负责将视频中的语音转换为带时间戳的文本。
- 音频提取不依赖 ffmpeg 命令行。它使用
av(PyAV) 库直接从视频容器中解码音频流,并通过av.AudioResampler重采样为 16kHz 单声道 16-bit WAV——这是 Whisper 模型的标准输入格式。这种方式避免了外部进程调用,兼容性更好。 - 本地推理,隐私可控。 transcription 由
faster-whisper在本地完成,支持 tiny/base/small/medium/large-v2/large-v3 多种模型尺寸。如果安装了torch且有 CUDA,会自动切换到 GPU (float16) 加速;否则运行在 CPU (int8) 上。 - VAD 过滤。转录时启用
vad_filter=True,自动过滤掉静音和背景噪声片段,提升长视频的处理效率和识别准确率。 - 断点续传。若输出目录已存在同名的
.srt文件,且未指定--no-skip,则直接从现有 SRT 加载结果,跳过转录步骤。
2. 智能分段:按主题切分字幕
转录得到的是按时间顺序排列的原始字幕,下一步需要按“知识点”或“主题”进行语义分组。segment_video.py 调用文本 LLM 完成这一任务。
- Prompt 工程。系统 Prompt 明确告诉 LLM:每个段落应围绕一个相对独立的主题展开;当视频中有“第一/第二/第三”、“首先/其次/最后”、“步骤1/步骤2”等明确序号标记时,必须按这些标记切分;过渡句不要单独成段。
- 严格 JSON 输出。LLM 被要求直接返回形如
{"sections": [[1, 15], [16, 30], [31, 49]]}的 JSON,表示每个主题段落的字幕序号闭区间。脚本通过正则提取 JSON 并解析。 - 上下文增强。为了帮 LLM 理解整体语境,脚本会将视频的绝对路径作为
video_title传入。文件名和目录结构往往包含课程名称、讲师、章节等信息,能辅助 LLM 做出更准确的分段判断。 - 容错降级。若 LLM 返回的格式异常或 JSON 解析失败,脚本不会崩溃,而是自动降级为“整段处理”(把所有字幕当作一个段落),保证流程的鲁棒性。
- 结构化中间产物。分段结果保存为 JSON,记录每个段落的
start_index、end_index、start_time、end_time和 preview 文本,方便人工检查或调试。
3. 视频帧提取:精准定位关键画面
merge_segments.py 中的 extract_frames 负责从视频中提取与字幕对应的画面。
- 基于 PTS 的精准定位。使用
av库打开视频后,读取视频流的average_rate(帧率)和time_base(时间基)。对于每个字幕片段,计算其中点时刻,将其转换为 Presentation Timestamp (PTS),然后调用container.seek(target_pts, stream=stream)快速跳转到目标位置附近,再逐帧解码直到找到时间匹配的帧,保存为 JPEG。 - 跳过已提取帧。如果目标帧图片已存在于
frames/目录中,则直接复用,避免重复的磁盘 I/O 和视频解码开销。
4. 帧-字幕对齐与采样压缩
一个主题段落可能包含几十条字幕,如果全部发给 VLM,token 成本会很高。因此脚本实现了帧-字幕对齐和采样压缩。
_build_merged_pairs的对齐逻辑:- 首先筛选出成功提取到帧的字幕位置;
- 若有效帧数超过
max_frames(默认 8),则进行等距均匀采样; - 以采样点为界,将相邻字幕合并成一个新的“虚拟片段”。
- 一一对应。最终返回的
merged_segs(合并后的字幕列表)和sampled_frames(采样帧路径)长度严格相等,每个帧只对应一段合并后的字幕文本。这保证了 VLM 每次接收的输入被精确控制在max_frames个图文对以内。
5. VLM 汇总:滚动摘要与知识提炼
SrtMerger 调用视觉语言模型(VLM),结合字幕和关键帧生成 Markdown 笔记。这是整个流程中最关键的环节。
- 多模态输入构造。
_build_content构建的 messages 是一个多模态列表,包含:【视频主题】:视频的绝对路径,为 VLM 提供整体语境;【已整理摘要】:前一段落生成的压缩摘要(滚动上下文);【当前段落】:时间戳 + 合并后的字幕文本 + base64 编码的关键帧图片。
- 滚动压缩摘要机制。长视频往往有几十个段落,一次性把所有上下文塞给 VLM 不现实。因此脚本设计了一个滚动摘要:处理完第 N 个段落后,VLM 会输出一个 300 字以内的
summary,这个摘要会被带入第 N+1 个段落的请求中。这样 VLM 不需要回顾所有历史输出,只需要读取一段短摘要就能把握整体脉络,同时保持跨段落连贯性。 - 严格的输出约束。System Prompt 强制要求 VLM 返回 JSON
{"note": "...", "summary": "..."},并对note字段做了严格规范:- 必须使用 Markdown 格式,但标题用加粗(
**标题**)而不是#层级,避免与最终笔记的章节结构冲突; - 聚焦概念定义、方法论、actionable insights、对比结论、数据观点;
- 禁止描述画面场景、人物动作、讲师外貌、视频形式;
- 禁止使用“视频中提到”、“讲师说”、“我们可以看到”等引导词,直接陈述知识点本身。
- 必须使用 Markdown 格式,但标题用加粗(
- 容错解析。
_parse_response会用正则从 VLM 输出中提取 JSON。如果解析失败,则回退到原始文本或合并字幕文本,确保不会因为模型输出格式偏差而导致整个流程中断。
6. 笔记组装:统一的 Markdown 输出
所有段落处理完毕后,build_note 函数将结果组装成最终的 note.md。
- YAML frontmatter:包含
title和segments(段落数量)。 - 段落结构:每个段落独立成章,包含:
- 段落序号标题;
- 时间范围(如
00:05:30 - 00:08:12); - 笔记(VLM 生成的 Markdown 知识点);
- 关键帧(相对路径引用的
frames/目录下的图片)。
生成的笔记可以直接拖入 Obsidian vault,其中的图片引用使用相对路径,在任何支持 Markdown 的编辑器中都能正常渲染。
五、总结
Video Knowledge Purify 的核心价值,是把视频从“一次性消费”变成“可检索、可复习、可沉淀”的结构化知识资产。
在信息获取越来越依赖视频的今天,这个 Skill 解决了一个非常具体的痛点:我们知道视频里有很多有价值的内容,但缺乏高效的手段将其提取出来并纳入个人知识库。通过本地 Whisper 转录 + LLM 语义分段 + VLM 多模态汇总的流水线,它把原本需要花费数小时的手动整理工作压缩到了几分钟的自动化流程中。
然而,它的有效运转也依赖几个前提:
- 转录质量取决于音频清晰度和模型大小。如果视频背景嘈杂、口音较重,或者使用了 tiny/base 等轻量模型,转录错误会向后传递到分段和汇总环节。对于高质量输出,建议使用 medium 及以上模型。
- 分段和汇总质量取决于 LLM/VLM 的能力。分段模型需要对中文语境下的序号标记、过渡句有较好的理解;VLM 需要能同时阅读文字和画面,并按照 Prompt 约束去除“视频描述”而保留“知识提炼”。
- 长视频处理时间较长。一个 1 小时的视频,Whisper 转录可能需要 5-15 分钟,LLM 分段 1-2 分钟,VLM 汇总每个段落 5-10 秒,整体仍可能需要数十分钟。建议对长视频采用更强的硬件或更小的
max_frames参数。
这个 Skill 适合任何希望将视频课程、技术分享、会议录像转化为个人知识笔记的场景。它不会替代你的思考和理解,但它能把你从繁琐的格式转换和信息搬运中解放出来,让你把精力集中在真正重要的事情上——学习和应用知识。

