Part 1:基本概念
概念
强化学习
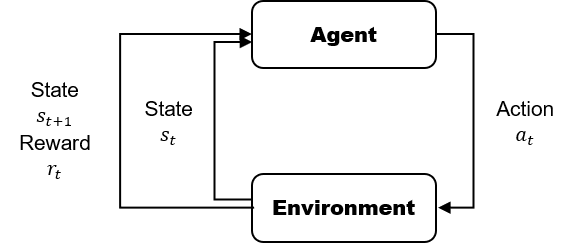
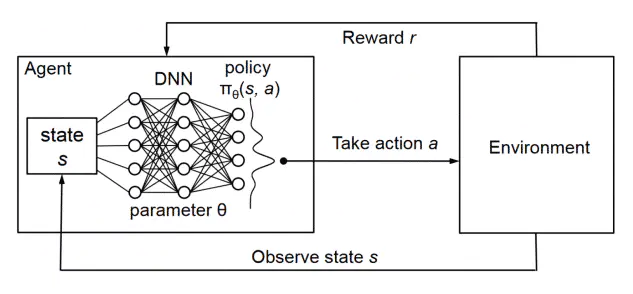
强化学习关注与智能体(agent)如何与环境交互中不断学习以完成特定的目标;
与有监督学习相比,不需要告诉智能体数据以及对应的标签,学习相应的模型,而是需要智能体在环境中一次次学习(哪些数据对应哪些标签),从而学习规律知道策略;
强化学习是希望智能体在环境中根据当前状态,采取行动,转移到下一个状态,获得回报。不断进行这样的过程,从而学习到一个策略(状态到动作的映射,即当前状态下,采取什么样的行动,能使得我最终获得的回报最大【不仅只是当前状态的而回报,一个策略的长期影响才是至关重要的】)
( s 1 ) → a 1 ( s 2 / r 1 ) → a 2 ( s 3 / r 2 ) → a 3 ( s 4 / r 3 ) → ⋯ (s_1) \rightarrow^{a_1} (s_2/r_1) \rightarrow^{a_2} (s_3/r_2) \rightarrow^{a_3} (s_4/r_3) \rightarrow \cdots
( s 1 ) → a 1 ( s 2 / r 1 ) → a 2 ( s 3 / r 2 ) → a 3 ( s 4 / r 3 ) → ⋯
交互对象
智能体(agent):可以感知外界环境的状态(state)和反馈的奖励(reward),并进行学习和决策.智能体的决策功能是指根据外界环境的状态来做出不同的动作(action),而学习功能是指根据外界环境的奖励来调整策略(policy);
环境(environment):是智能体外部的所有事物,并受智能体动作的影响而改变其状态,并反馈给智能体相应的奖励。
基本要素
基础概念定义
在步骤t t t
状态 (state):对环境的描述,s t s_t s t
动作 (action):对智能体行为的描述,a t a_t a t
策略 (policy):是一组概率分布,表示每个动作的概率,π ( a ∣ s ) \pi(a|s) π ( a ∣ s )
奖励 (reward):智能体做出动作a t a_t a t s t + 1 s_{t+1} s t + 1 r t r_t r t
回报 (return):智能体在某状态下,未来多个奖励状态的总和。t t t γ \gamma γ t t t g t g_t g t
g t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ = ∑ k = 0 N γ k r t + k g_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots = \sum_{k=0}^N \gamma^k r_{t+k}
g t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ = k = 0 ∑ N γ k r t + k
有递归式:
g t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ = r t + γ ( r t + 1 + γ r t + 2 + ⋯ ) = r t + γ g t + 1 \begin{aligned}
g_t &= r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots \\
&= r_t + \gamma (r_{t+1} + \gamma r_{t+2} + \cdots) \\
&= r_t + \gamma g_{t+1}
\end{aligned}
g t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ = r t + γ ( r t + 1 + γ r t + 2 + ⋯ ) = r t + γ g t + 1
状态价值函数 (state-value function):V值,是从状态s t s_t s t π \pi π
V π ( s t ) = E π [ G ∣ S = s t ] V^\pi(s_t) = E_\pi[G|S=s_t]
V π ( s t ) = E π [ G ∣ S = s t ]
有贝尔曼方程 (Bellman Equation),具体推导见状态价值函数和动作价值函数的关系
V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ] V^{\pi}(s_t) = E_\pi[r_t + \gamma V^{\pi}(s_{t+1}) | S=s_t]
V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ]
贝尔曼方程 (Bellman Equation)也被称作动态规划方程(Dynamic Programming Equation),由理查·贝尔曼(Richard Bellman)发现。贝尔曼方程是动态规划(Dynamic Programming)这些数学最佳化方法能够达到最佳化的必要条件。此方程把“决策问题在特定时间怎么的值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。借此这个方式把动态最佳化问题变成简单的子问题,而这些子问题遵守从贝尔曼所提出来的“最佳化还原理”。
动作价值函数 (action-value function):Q值,是在当前状态s t s_t s t a t a_t a t p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t, a_t) p ( s t + 1 ∣ s t , a t ) s t + 1 s_{t+1} s t + 1 r t r_t r t r t r_t r t s t + 1 s_{t+1} s t + 1 π \pi π
Q π ( s t , a t ) = E π [ G ∣ S = s t , A = a t ] Q^\pi(s_t, a_t) = E_\pi[G|S=s_t, A=a_t]
Q π ( s t , a t ) = E π [ G ∣ S = s t , A = a t ]
可以用动作价值函数判断t t t
a ∗ = arg max a Q ( s , a ) a^* = \argmax_a Q(s, a)
a ∗ = a arg max Q ( s , a )
优势函数 (advantage function):表示状态s t s_t s t a t a_t a t
A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t ) A^\pi(s_t, a_t) = Q^\pi(s_t, a_t) - V^\pi(s_t)
A π ( s t , a t ) = Q π ( s t , a t ) − V π ( s t )
TD误差 (TD error):是当前状态的奖励与下一个状态的预期奖励之差,这个差异反映了当前状态与预期状态的差异,因此通常被用来更新策略网络的参数。用来帮助强化学习模型在经历一系列状态后发现自己认为的最优策略与实际的最优策略之间的差距,从而帮助模型更快地学习。根据贝尔曼方程V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ] V^{\pi}(s_t) = E_\pi[r_t + \gamma V^{\pi}(s_{t+1}) | S=s_t] V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ] ( r t + γ V π ( s t + 1 ) ) (r_t + \gamma V^{\pi}(s_{t+1})) ( r t + γ V π ( s t + 1 )) Q π ( s t , a t ) Q^\pi(s_t, a_t) Q π ( s t , a t )
δ ( t ) = r t + γ V π ( s t + 1 ) − V π ( s t ) \delta(t) = r_t + \gamma V^{\pi}(s_{t+1}) - V^{\pi}(s_{t})
δ ( t ) = r t + γ V π ( s t + 1 ) − V π ( s t )
TD误差的一个好处是,模型只需要根据状态s s s s s s a a a
状态价值函数和动作价值函数的关系
一个状态的V V V s t s_t s t a t ∈ A a_t \in A a t ∈ A Q Q Q π \pi π
V π ( s t ) = E a ∼ π ( a t ∣ s t ) Q π ( s t , a ) = ∑ a ∈ A π ( a ∣ s t ) ⋅ Q π ( s t , a ) \begin{aligned}
V^\pi(s_t) &= E_{a \sim \pi(a_t|s_t)} Q^\pi(s_t, a) \\
&= \sum_{a \in A} \pi(a|s_t) \cdot Q^\pi(s_t, a)
\end{aligned}
V π ( s t ) = E a ∼ π ( a t ∣ s t ) Q π ( s t , a ) = a ∈ A ∑ π ( a ∣ s t ) ⋅ Q π ( s t , a )
一个动作的Q值,是在状态s t s_t s t a t a_t a t p ( s ∣ s t , a t ) p(s|s_t, a_t) p ( s ∣ s t , a t ) p ( r ∣ s t , a t ) p(r|s_t, a_t) p ( r ∣ s t , a t )
Q π ( s t , a t ) = E r ∼ p ( r ∣ s t , a t ) , s ∼ p ( s ∣ s t , a t ) ( r + V π ( s ) ) = ∑ r ∈ R p ( r ∣ s t , a t ) r + ∑ s ∈ S p ( s ∣ s t , a t ) V π ( s ) \begin{aligned}
Q^\pi(s_t, a_t) &= E_{r \sim p(r|s_t, a_t), s \sim p(s|s_t, a_t)} \left( r + V^\pi(s) \right) \\
&= \sum_{r \in R} p(r|s_t, a_t) r + \sum_{s \in S} p(s|s_t, a_t) V^\pi(s)
\end{aligned}
Q π ( s t , a t ) = E r ∼ p ( r ∣ s t , a t ) , s ∼ p ( s ∣ s t , a t ) ( r + V π ( s ) ) = r ∈ R ∑ p ( r ∣ s t , a t ) r + s ∈ S ∑ p ( s ∣ s t , a t ) V π ( s )
实际应用中,一般加上折扣率γ \gamma γ
Q π ( s t , a t ) = ∑ r ∈ R p ( r ∣ s t , a t ) r + γ ∑ s ∈ S p ( s ∣ s t , a t ) V π ( s ) Q^\pi(s_t, a_t) = \sum_{r \in R} p(r|s_t, a_t) r + \gamma \sum_{s \in S} p(s|s_t, a_t) V^\pi(s)
Q π ( s t , a t ) = r ∈ R ∑ p ( r ∣ s t , a t ) r + γ s ∈ S ∑ p ( s ∣ s t , a t ) V π ( s )
把Q π ( s t , a t ) Q^\pi(s_t, a_t) Q π ( s t , a t ) V π ( s t ) V^\pi(s_t) V π ( s t )
V π ( s t ) = ∑ a ∈ A π ( a ∣ s t ) ⋅ Q π ( s t , a ) = ∑ a ∈ A π ( a ∣ s t ) ⋅ ( ∑ r ∈ R p ( r ∣ s t , a ) r + γ ∑ s ∈ S p ( s ∣ s t , a ) V π ( s ) ) \begin{aligned}
V^\pi(s_t) &= \sum_{a \in A} \pi(a|s_t) \cdot Q^\pi(s_t, a) \\
&= \sum_{a \in A} \pi(a|s_t) \cdot \left(
\sum_{r \in R} p(r|s_t, a) r + \gamma \sum_{s \in S} p(s|s_t, a) V^\pi(s)
\right)
\end{aligned}
V π ( s t ) = a ∈ A ∑ π ( a ∣ s t ) ⋅ Q π ( s t , a ) = a ∈ A ∑ π ( a ∣ s t ) ⋅ ( r ∈ R ∑ p ( r ∣ s t , a ) r + γ s ∈ S ∑ p ( s ∣ s t , a ) V π ( s ) )
当时刻t t t a t a_t a t r t r_t r t s t + 1 s_{t+1} s t + 1
V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ] V^{\pi}(s_t) = E_\pi[r_t + \gamma V^{\pi}(s_{t+1}) | S=s_t]
V π ( s t ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ]
上面的几个定义式理解起来比较抽象,举个例子
假如每一步的状态空间是S = { s a , s b , s c , s d } S = \{s_a, s_b, s_c, s_d\} S = { s a , s b , s c , s d } A = { a x , a y , a z } A = \{a_x, a_y, a_z\} A = { a x , a y , a z }
序列一:( s 1 1 = s a ) → a 1 1 = a x ( s 2 1 = s b / r 1 1 ) → a 2 1 = a y ( s 3 1 = s c / r 2 1 ) → a 3 1 = a z ( s 4 1 = s d / r 3 1 ) (s^1_1=s_a) \rightarrow^{a^1_1=a_x} (s^1_2=s_b/r^1_1) \rightarrow^{a^1_2=a_y} (s^1_3=s_c/r^1_2) \rightarrow^{a^1_3=a_z} (s^1_4=s_d/r^1_3) ( s 1 1 = s a ) → a 1 1 = a x ( s 2 1 = s b / r 1 1 ) → a 2 1 = a y ( s 3 1 = s c / r 2 1 ) → a 3 1 = a z ( s 4 1 = s d / r 3 1 )
序列二:( s 1 2 = s a ) → a 1 2 = a x ( s 2 2 = s b / r 1 2 ) → a 2 2 = a z ( s 3 2 = s d / r 2 2 ) (s^2_1=s_a) \rightarrow^{a^2_1=a_x} (s^2_2=s_b/r^2_1) \rightarrow^{a^2_2=a_z} (s^2_3=s_d/r^2_2) ( s 1 2 = s a ) → a 1 2 = a x ( s 2 2 = s b / r 1 2 ) → a 2 2 = a z ( s 3 2 = s d / r 2 2 )
奖励函数这样设置:如果最终胜利,那么r t = 1 r_{t} = 1 r t = 1 r t = 0 r_{t} = 0 r t = 0
状态s b s_b s b a y , a z a_y, a_z a y , a z s c , s d s_c, s_d s c , s d π ( s c ∣ s b ) = π ( s d ∣ s b ) = 0.5 \pi(s_c|s_b) = \pi(s_d|s_b) = 0.5 π ( s c ∣ s b ) = π ( s d ∣ s b ) = 0.5
在状态s b s_b s b a y a_y a y g 2 1 = ( r 2 1 + 0.9 × r 3 1 ) = 1.9 g^1_2 = (r^1_2 + 0.9 \times r^1_3) = 1.9 g 2 1 = ( r 2 1 + 0.9 × r 3 1 ) = 1.9 s b s_b s b a y a_y a y Q π ( s b , a y ) = 1.9 Q^\pi(s_b, a_y) = 1.9 Q π ( s b , a y ) = 1.9
在状态s b s_b s b a z a_z a z g 2 2 = r 2 2 = 0 g^2_2 = r^2_2 = 0 g 2 2 = r 2 2 = 0 s b s_b s b a z a_z a z Q π ( s b , a z ) = 0 Q^\pi(s_b, a_z) = 0 Q π ( s b , a z ) = 0
状态s b s_b s b V π ( s b ) = π ( s c ∣ s b ) × Q π ( s b , a y ) + π ( s d ∣ s b ) × Q π ( s b , a z ) = 0.475 V^\pi(s_b) = \pi(s_c|s_b) \times Q^\pi(s_b, a_y) + \pi(s_d|s_b) \times Q^\pi(s_b, a_z) = 0.475 V π ( s b ) = π ( s c ∣ s b ) × Q π ( s b , a y ) + π ( s d ∣ s b ) × Q π ( s b , a z ) = 0.475
那么在状态s b s_b s b a y a_y a y A π ( s b , a y ) = Q π ( s b , a y ) − V π ( s b ) = 0.475 A^{\pi}(s_b, a_y) = Q^\pi(s_b, a_y) - V^\pi(s_b) = 0.475 A π ( s b , a y ) = Q π ( s b , a y ) − V π ( s b ) = 0.475 a z a_z a z A π ( s b , a z ) = Q π ( s b , a z ) − V π ( s b ) = − 0.475 A^{\pi}(s_b, a_z) = Q^\pi(s_b, a_z) - V^\pi(s_b) = -0.475 A π ( s b , a z ) = Q π ( s b , a z ) − V π ( s b ) = − 0.475 a y a_y a y a z a_z a z
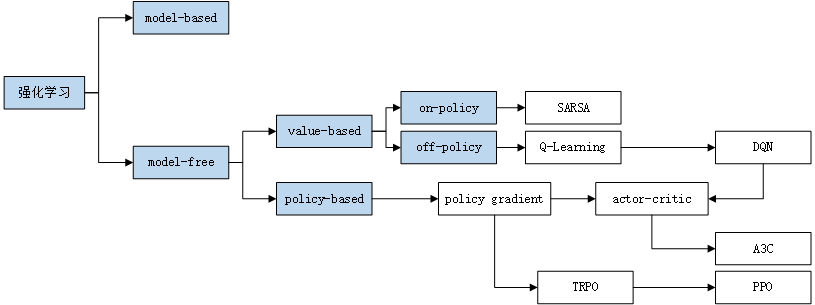
分类
value-based & policy-based
value-based:训练Q ( s , a ) Q(s, a) Q ( s , a ) s s s a a a
policy-based:训练p ( s , a ) p(s, a) p ( s , a ) s s s a a a a a a
也有将两种方法结合,如actor-critic
on-policy & off-policy
on-policy:行动策略和评估策略相同,需要学习的Agent和训练过程中和环境进行交互的Agent是同一个,如SARSA
off-policy:行动策略和评估策略不相同,需要学习的Agent和训练过程中真正和环境进行交互的Agent不是同一个,如Q-Learning
model-based & model-free
model-based相对于model-free的最主要区别是引入了对环境的建模。这里提到的建模是指我们通过监督训练来训练一个环境模型,其数据是算法和环境的实际交互数据( s t , a t , r t , s t + 1 , a t + 1 , r t + 1 , ⋯ ) (s_t, a_t, r_t, s_{t+1}, a_{t+1}, r_{t+1}, \cdots) ( s t , a t , r t , s t + 1 , a t + 1 , r t + 1 , ⋯ ) s t s_t s t a t a_t a t s t + 1 s_{t+1} s t + 1
model-based:使用环境模型(环境的动态特性,即期望收益和状态转移概率)和规划(在真正经历之前,先考虑未来可能发生的各种情境从而预先决定采取何种动作)来解决强化学习问题的方法。
model-free::通过学习(直接地试错)经验(在与环境交互中采样得到的状态、动作、收益序列)来解决强化学习问题的方法。
在agent执行它的动作之前,它是否能对下一步的状态和回报做出预测,如果可以,那么就是model-based方法(model based方法就好比人类对环境的转移有一个初步的预估,所以plan了一个更好的action),如果不能,即为model-free方法。
offline reinforcement learning
离线强化学习,即用大量过往数据进行学习,没有交互环境参与。
Part 2: 从Q-Learning到DQN
Q-Learning
Q-Learning是根据所经历的状态和所选择的行为建立一张Q表格(Q-Table),根据每一轮学习到的奖励更新Q表格。Q-Table即以状态为行、动作为列建立的表格,存放Q值。问题在于,如何求取Q-Table中的Q值。
状态\动作
a 0 a_0 a 0 a 1 a_1 a 1 a 2 a_2 a 2 ⋯ \cdots ⋯
s 0 s_0 s 0
s 1 s_1 s 1
s 1 s_1 s 1
⋯ \cdots ⋯
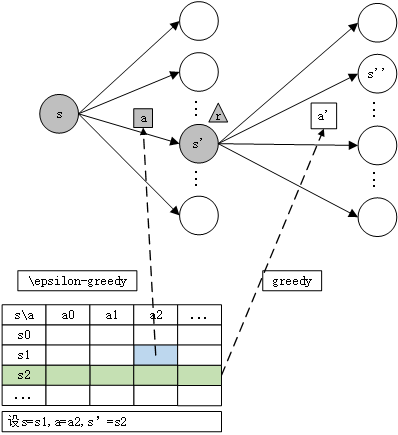
用s s s a a a r r r s ′ s' s ′
1 2 3 4 5 6 7 8 9 Initialize Q(s, a) arbitrarily Repeat (for each episode): Initialize s Repeat (for each step of episode): Choose a from s using policy derived from Q (e.g. \epsilon-greedy) Take action a, observe r, s' Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right] s \leftarrow s' until s is terminal
其中,ϵ − g r e e d y \epsilon-greedy ϵ − g ree d y p p p Q ( s , a ) Q(s, a) Q ( s , a ) a a a ϵ \epsilon ϵ ϵ \epsilon ϵ 1 − ϵ 1 - \epsilon 1 − ϵ ϵ \epsilon ϵ
a = { arg max a ′ ∈ A Q ( s , a ′ ) p < ϵ random a ′ ∈ A a ′ otherwise a = \begin{cases}
\argmax_{a' \in A} Q(s, a') & p < \epsilon \\
\text{random}_{a' \in A} a' & \text{otherwise}
\end{cases}
a = { arg max a ′ ∈ A Q ( s , a ′ ) random a ′ ∈ A a ′ p < ϵ otherwise
按时间步展开,图例如下,注意在时刻t t t ( s , a , s ′ , r ) (s, a, s', r) ( s , a , s ′ , r )
参数更新公式如下,α \alpha α
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) ‾ − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[
\underline{r + \gamma \max_{a'} Q(s', a')} - Q(s, a)
\right]
Q ( s , a ) ← Q ( s , a ) + α [ r + γ a ′ max Q ( s ′ , a ′ ) − Q ( s , a ) ]
根据Q值选择每步的最佳动作,也就是a ′ = arg max a Q ( s ′ , a ) a' = \argmax_a Q(s', a) a ′ = arg max a Q ( s ′ , a ) max a ′ Q ( s ′ , a ′ ) \max_{a'} Q(s', a') max a ′ Q ( s ′ , a ′ ) s ′ s' s ′ a ′ ∈ A a' \in A a ′ ∈ A r + γ max a ′ Q ( s ′ , a ′ ) r + \gamma \max_{a'} Q(s', a') r + γ max a ′ Q ( s ′ , a ′ ) Q ( s , a ) Q(s, a) Q ( s , a )
下面的Q-Learning例程,是智能体在长度为N_STATES的一维空间中探索的例子,当N_STATES=6该空间表示为-----T。智能体从最左侧出发,即o----T,探索一条路线到达终点T。Q-Table设置为
位置(s)\方向(a)
left
right
0
1
2
3
4
5(T)
Q-Learning例程:是智能体在长度为N_STATES的一维空间中探索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import numpy as npimport pandas as pdimport timenp.random.seed(42 ) N_STATES = 6 ACTIONS = ['left' , 'right' ] EPSILON = 0.9 ALPHA = 0.1 GAMMA = 0.9 MAX_EPISODES = 10 FRESH_TIME = 0.3 def build_q_table (n_states, actions ): """ 新建Q表格,Q(s, a)表示在位置s处采取a行为的行为值 """ table = pd.DataFrame( np.zeros((n_states, len (actions))), columns=actions, ) return table """ left right 0 0.0 0.0 1 0.0 0.0 2 0.0 0.0 3 0.0 0.0 4 0.0 0.0 5 0.0 0.0 """ def choose_action (state, q_table ): """ 以\epsilon-greedy策略,选择当前s处选择的动作a 以90%概率贪婪选择,10%概率随机选择 """ state_actions = q_table.iloc[state, :] if (np.random.uniform() > EPSILON) or (state_actions.any () == 0 ): action_name = np.random.choice(ACTIONS) else : action_name = state_actions.idxmax() return action_name def get_env_feedback (S, A ): """ 在位置s处采取动作a,求取状态s'、奖励r """ if A == 'right' : if S == N_STATES - 2 : S_ = 'terminal' R = 1 else : S_ = S + 1 R = 0 else : R = 0 if S == 0 : S_ = S else : S_ = S - 1 return S_, R def update_env (S, episode, step_counter ): env_list = ['-' ] * (N_STATES - 1 ) + ['T' ] if S == 'terminal' : interaction = 'Episode %s: total_steps = %s' % (episode + 1 , step_counter) print ('\r{}' .format (interaction), end='' ) time.sleep(1 ) print ('\r ' , end='' ) else : env_list[S] = 'o' interaction = '' .join(env_list) print ('\r[{} - {}] {}' .format (episode, step_counter, interaction), end='' ) time.sleep(FRESH_TIME) def rl (): q_table = build_q_table(N_STATES, ACTIONS) for episode in range (MAX_EPISODES): step_counter = 0 S = 0 is_terminated = False update_env(S, episode, step_counter) while not is_terminated: A = choose_action(S, q_table) S_, R = get_env_feedback(S, A) q_predict = q_table.loc[S, A] if S_ != 'terminal' : q_target = R + GAMMA * q_table.iloc[S_, :].max () else : q_target = R is_terminated = True q_table.loc[S, A] += ALPHA * (q_target - q_predict) step_counter += 1 ; S = S_ update_env(S, episode, step_counter) print (f"episode {episode} \n" , q_table) return q_table if __name__ == "__main__" : q_table = rl() print ('\r\nQ-table:\n' ) print (q_table)
迭代过程中的Q-Table取值情况如下,可以看到Q是从t + 1 → t t+1 \rightarrow t t + 1 → t
位置(s)\方向(a)
1/left
1/right
2/left
2/right
3/left
3/right
4/left
4/right
5/left
5/right
6/left
6/right
7/left
7/right
8/left
8/right
9/left
9/right
10/left
10/right
0
0
0
0
0
0
0
0
0
0
6.561e-06
0
3.60855e-05
0
0.000115802
0
0.000283206
0
0.000584533
0
0.00107268
1
0
0
0
0
0
0
0
7.29e-05
0
0.00033534
0
0.00092583
0
0.00198871
0
0.00366275
0
0.00607337
0
0.0093277
2
0
0
0
0
0
0.00081
0
0.002997
0
0.0069336
0
0.0128385
0
0.0208101
0
0.0308543
0
0.0429074
0
0.0568546
3
0
0
0
0.009
0
0.0252
0
0.04707
0
0.073314
0
0.102839
0
0.134725
0
0.168206
0
0.202643
0
0.237511
4
0
0.1
0
0.19
0
0.271
0
0.3439
0
0.40951
0
0.468559
0
0.521703
0
0.569533
0
0.61258
0
0.651322
5
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
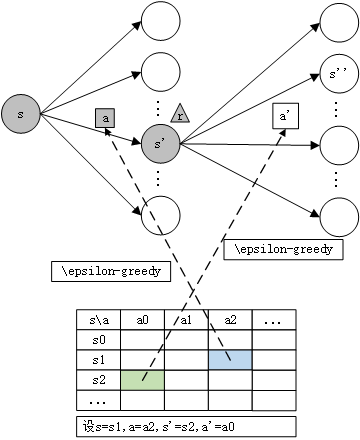
SARSA
全称是State-Action-Reward-State’-Action’
1 2 3 4 5 6 7 8 9 10 Initialize Q(s, a) arbitrarily Repeat (for each episode): Initialize s Repeat (for each step of episode): Choose a from s using policy derived from Q (e.g. \epsilon-greedy) Take action a, observe r, s' Choose a' from s' using policy derived from Q (e.g. \epsilon-greedy) Q(s, a) \leftarrow Q(s, a) + \alpha \left[ \underline{r + \gamma Q(s', a')} - Q(s, a) \right] s \leftarrow s'; a \leftarrow a' until s is terminal
与Q-Learning的区别在于更新方式不同,在下一状态s ′ s' s ′ a ′ a' a ′ G t = R t + γ G t + 1 G_t = R_t + \gamma G_{t+1} G t = R t + γ G t + 1
Q ( s , a ) ← Q ( s , a ) + α [ r + γ Q ( s ′ , a ′ ) ‾ − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[
\underline{r + \gamma Q(s', a')} - Q(s, a)
\right]
Q ( s , a ) ← Q ( s , a ) + α [ r + γ Q ( s ′ , a ′ ) − Q ( s , a ) ]
与Q-Learning的区别:,Q-learning是选取s ′ s' s ′ s ′ s' s ′ a ′ a' a ′
DQN
在状态空间S S S A A A ( s , a ) (s, a) ( s , a ) DQN用神经网络模型拟合函数Q ( s , a ) Q(s, a) Q ( s , a )
伪代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Initialize relay memory D to capacity N # experience replay Initialize action-value function Q with random weights \theta # Q-Function Initialize target action-value function \hat{Q} with weights \theta^- = \theta For episode = 1, M do Initialize sequence s_1 = \{x_1\} and preprocessed sequence \phi_1 = \phi(s_1) For t = 1, T do With probability \epsilon select a random action a_t \ otherwise select a_t = \argmax_{a} Q(\phi(s_t), a; \theta) # \epsilon-greedy Execute action a_t in emulator and observe reward r_t and image x_{t + 1} # environment reaction Set s_{t + 1} = s_t, a_t, x_{t + 1} and preprocess \phi_{t + 1} = \phi(s_{t + 1}) Store transition (\phi_t, a_t, r_t, \phi_{t + 1}) in D # experience replay Sample random minibatch of transitions (\phi_j, a_j, r_j, \phi_{j + 1})_{j = 1, \cdots, B} from D set y_j = \begin{cases} r_j & \text{if episode terminates at step j + 1} \\ r_j + \gamma \max_{a'} \hat{Q}(\phi_{j + 1}, a'; \theta^-) & \text{otherwise} \end{cases} Perform a gradient descent step on L_j = \left( y_j - Q(\phi_j, a_j; \theta) \right)^2 with respect to the network parameters \theta Every C steps reset \hat{Q} = Q # fixed-q-target End For End For
其中a t a_t a t ϵ − g r e e d y \epsilon-greedy ϵ − g ree d y
a t = { arg max a Q ( ϕ ( s t ) , a ; θ ) p < ϵ random a ∈ A a otherwise a_t = \begin{cases}
\argmax_{a} Q(\phi(s_t), a; \theta) & p < \epsilon \\
\text{random}_{a \in A} a & \text{otherwise}
\end{cases}
a t = { arg max a Q ( ϕ ( s t ) , a ; θ ) random a ∈ A a p < ϵ otherwise
其中ϕ ( s ) \phi(s) ϕ ( s ) s s s ϕ t = ϕ ( s t ) \phi_t = \phi(s_t) ϕ t = ϕ ( s t )
L j = ( y j − Q ( ϕ j , a j ; θ ) ) 2 L_j = \left( y_j - Q(\phi_j, a_j; \theta) \right)^2
L j = ( y j − Q ( ϕ j , a j ; θ ) ) 2
其中
y j = { r j if episode terminates at step j + 1 r j + γ max a ′ Q ^ ( ϕ j + 1 , a ′ ; θ − ) otherwise y_j = \begin{cases}
r_j & \text{if episode terminates at step j + 1} \\
r_j + \gamma \max_{a'} \hat{Q}(\phi_{j + 1}, a'; \theta^-) & \text{otherwise}
\end{cases}
y j = { r j r j + γ max a ′ Q ^ ( ϕ j + 1 , a ′ ; θ − ) if episode terminates at step j + 1 otherwise
从伪代码可以看出,DQN主要作出了以下三个贡献
将Q-Table参数化得到Q-Function,并用神经网络拟合;
经验回放(Experience Replay):
强化学习采集数据的过程非常慢,如果能将互动过程中的数据缓存起来,每步就可以通过采样一批数据进行参数更新
强化学习采集的数据之间存在关联性,而深度神经网络训练中要求数据满足独立同分布,因此直接用相邻时间步的数据会使模型训练不稳定,而经验回放通过采样的方式可以打破数据间的关联;
当超出容量N N N
目标网络(Fixed-Q-Target):训练过程中使用了评估网络Q Q Q Q ^ \hat{Q} Q ^ Q Q Q θ \theta θ Q ^ \hat{Q} Q ^ θ − \theta^- θ − C C C Q Q Q
实际上,DQN参数更新可以表示为下式,在形式上与Q-Learning保持一致
θ ← θ + α [ r j + γ max a ′ Q ^ ( ϕ j + 1 , a ′ ; θ − ) − Q ( ϕ j , a j ; θ ) ] ∇ Q ( ϕ j , a j ; θ ) \theta \leftarrow \theta + \alpha \left[
r_j + \gamma \max_{a'} \hat{Q}(\phi_{j + 1}, a'; \theta^-) - Q(\phi_j, a_j; \theta)
\right] \nabla Q(\phi_j, a_j; \theta)
θ ← θ + α [ r j + γ a ′ max Q ^ ( ϕ j + 1 , a ′ ; θ − ) − Q ( ϕ j , a j ; θ ) ] ∇ Q ( ϕ j , a j ; θ )
DQN的三大变体
Double DQN:目标值估计的改进,缓解过估计问题
因为DQN是off-policy方法,每次学习时,不是使用下一次交互的真实动作,而是使用当前认为价值最大的动作来更新目标值函数,因此Q值往往偏大,导致过估计(over estimate)。因此,一种直观的解决方案是再加入一个模型相互监察,而DQN中本来就有两个网络Q Q Q Q ^ \hat{Q} Q ^ Q ^ \hat{Q} Q ^ Q Q Q y j y_j y j arg max a ′ ( Q ( ϕ j + 1 , a ′ ; θ ) ) \argmax_{a'}(Q(\phi_{j + 1}, a'; \theta)) arg max a ′ ( Q ( ϕ j + 1 , a ′ ; θ )) a ′ a' a ′
y j = { r j if episode terminates at step j + 1 r j + γ Q ^ ( ϕ j + 1 , arg max a ′ ( Q ( ϕ j + 1 , a ′ ; θ ) ) ‾ ; θ − ) otherwise y_j = \begin{cases}
r_j & \text{if episode terminates at step j + 1} \\
r_j + \gamma \hat{Q}(\phi_{j + 1}, \underline{\argmax_{a'}(Q(\phi_{j + 1}, a'; \theta))}; \theta^-) & \text{otherwise}
\end{cases}
y j = { r j r j + γ Q ^ ( ϕ j + 1 , arg max a ′ ( Q ( ϕ j + 1 , a ′ ; θ )) ; θ − ) if episode terminates at step j + 1 otherwise
其中a j + 1 = arg max a ′ ( Q ( ϕ j + 1 , a ′ ; θ ) ) a_{j + 1} =\argmax_{a'}(Q(\phi_{j + 1}, a'; \theta)) a j + 1 = arg max a ′ ( Q ( ϕ j + 1 , a ′ ; θ )) Q Q Q ϕ j + 1 \phi_{j+1} ϕ j + 1 a j + 1 a_{j + 1} a j + 1
Dueling DQN:网络结构的改进
DQN没有显式地分离状态价值和优势函数。这会导致在某些情况下,算法难以准确地估计状态价值和优势函数,从而影响策略学习的效率。Dueling DQN是从网络结构上改进DQN,将动作值函数分为状态价值函数 V V V 优势函数 A A A A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) A π ( s , a ) = Q π ( s , a ) − V π ( s )
Q ( ϕ , a ; θ , α , β ) = V ( ϕ ; θ , β ) + A ( ϕ , a ; θ , α ) Q(\phi, a; \theta, \alpha, \beta) = V(\phi; \theta, \beta) + A(\phi, a; \theta, \alpha)
Q ( ϕ , a ; θ , α , β ) = V ( ϕ ; θ , β ) + A ( ϕ , a ; θ , α )
其中α \alpha α β \beta β V V V A A A V V V ϕ \phi ϕ A A A ϕ \phi ϕ a a a Q Q Q V V V A A A A A A a ∗ a^* a ∗
A ( ϕ , a ; θ , α ) ← A ( ϕ , a ; θ , α ) − max a ′ A ( ϕ , a ′ ; θ , α ) A(\phi, a; \theta, \alpha) \leftarrow A(\phi, a; \theta, \alpha) - \max_{a'} A(\phi, a'; \theta, \alpha)
A ( ϕ , a ; θ , α ) ← A ( ϕ , a ; θ , α ) − a ′ max A ( ϕ , a ′ ; θ , α )
也即
Q ( ϕ , a ; θ , α , β ) = V ( ϕ ; θ , β ) + ( A ( ϕ , a ; θ , α ) − max a ′ A ( ϕ , a ′ ; θ , α ) ) Q(\phi, a; \theta, \alpha, \beta) = V(\phi; \theta, \beta) + \left(
A(\phi, a; \theta, \alpha) - \max_{a'} A(\phi, a'; \theta, \alpha)
\right)
Q ( ϕ , a ; θ , α , β ) = V ( ϕ ; θ , β ) + ( A ( ϕ , a ; θ , α ) − a ′ max A ( ϕ , a ′ ; θ , α ) )
这样,对于∀ a ∗ ∈ A \forall a^* \in \mathcal{A} ∀ a ∗ ∈ A
a ∗ = arg max a ′ ∈ A Q ( ϕ , a ′ ; θ , α , β ) = arg max a ′ ∈ A A ( ϕ , a ′ ; θ , α ) a^* = \argmax_{a' \in \mathcal{A}} Q(\phi, a'; \theta, \alpha, \beta) = \argmax_{a' \in \mathcal{A}} A(\phi, a'; \theta, \alpha)
a ∗ = a ′ ∈ A arg max Q ( ϕ , a ′ ; θ , α , β ) = a ′ ∈ A arg max A ( ϕ , a ′ ; θ , α )
此时就有
Q ( ϕ , a ∗ ; θ , α , β ) = V ( ϕ ; θ , β ) Q(\phi, a^*; \theta, \alpha, \beta) = V(\phi; \theta, \beta)
Q ( ϕ , a ∗ ; θ , α , β ) = V ( ϕ ; θ , β )
作者又尝试了用平均代替了最大,即
Q ( ϕ , a ; θ , α , β ) = V ( ϕ ; θ , β ) + ( A ( ϕ , a ; θ , α ) − 1 ∣ A ∣ ∑ a ′ A ( ϕ , a ′ ; θ , α ) ) Q(\phi, a; \theta, \alpha, \beta) = V(\phi; \theta, \beta) + \left(
A(\phi, a; \theta, \alpha) - \frac{1}{|\mathcal{A}|} \sum_{a'} A(\phi, a'; \theta, \alpha)
\right)
Q ( ϕ , a ; θ , α , β ) = V ( ϕ ; θ , β ) + ( A ( ϕ , a ; θ , α ) − ∣ A ∣ 1 a ′ ∑ A ( ϕ , a ′ ; θ , α ) )
虽然使得值函数V V V A A A V V V A A A
解读 状态值函数V ( ϕ ; θ , β ) V(\phi; \theta, \beta) V ( ϕ ; θ , β ) ϕ \phi ϕ a a a Q ( ϕ , a ; θ , α , β ) − V ( ϕ ; θ , β ) Q(\phi, a; \theta, \alpha, \beta) - V(\phi; \theta, \beta) Q ( ϕ , a ; θ , α , β ) − V ( ϕ ; θ , β ) Q Q Q V V V Q − V > 0 Q - V > 0 Q − V > 0 a a a
Prioritized Replay Buffer:训练过程的改进
在传统DQN的经验池中,选择batch的数据进行训练是随机的,没有考虑样本的优先级关系。但其实不同的样本的价值是不同的,我们需要给每个样本一个优先级,并根据样本的优先级进行采样。
样本的优先级如何确定?我们可以用到 TD-error, 也就是 q-target - q-eval 来规定优先学习的程度. 如果 TD-error 越大, 就代表我们的预测精度还有很多上升空间, 那么这个样本就越需要被学习, 也就是优先级 p 越高。
有了 TD-error 就有了优先级 p, 那我们如何有效地根据 p 来抽样呢? 如果每次抽样都需要针对 p 对所有样本排序, 这将会是一件非常消耗计算能力的事. 文中提出了一种被称作SumTree的方法。
Part 3: 从Policy-Gradient到TROP/PPO/PPO2
基于策略和基于价值的强化学习方法有什么区别?
作者:郝伟https://www.zhihu.com/question/542423465/answer/2566685921
对于一个状态转移概率已知的马尔可夫决策过程,我们可以使用动态规划算法来求解。从决策方式来看,强化学习又可以划分为基于策略的方法和基于价值的方法。决策方式是智能体在给定状态下从动作集合中选择一个动作的依据,它是静态的,不随状态变化而变化。
在基于策略的强化学习方法中,智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。 而在基于价值的强化学习方法中,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。
基于价值迭代的方法只能应用在不连续的、离散 的环境下**(如围棋或某些游戏领域),对于动作集合规模庞大、动作连续 的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。
Policy Gradient
核心思想是直接优化策略网络(Policy Network)a = π ( a ∣ s ; θ ) a = \pi(a | s; \theta) a = π ( a ∣ s ; θ ) s s s a a a 一个动作奖励越大,那么增加其出现的概率,否则降低 ,这就是策略梯度的基本思想。
推导过程
给定策略网络π ( a ∣ s ; θ ) \pi(a | s; \theta) π ( a ∣ s ; θ ) τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ⋯ , s T , a T , r T } \tau = \{s_1, a_1, r_1, s_2, a_2, r_2, \cdots, s_T, a_T, r_T\} τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ⋯ , s T , a T , r T } a t a_t a t π ( a t ∣ s t ; θ ) \pi(a_t | s_t; \theta) π ( a t ∣ s t ; θ ) R θ ( τ ) = ∑ t r t R_{\theta}(\tau) = \sum_t r_t R θ ( τ ) = ∑ t r t P θ ( τ ) P_{\theta}(\tau) P θ ( τ ) T \Tau T R ‾ θ \overline{R}_{\theta} R θ
R ‾ θ = ∑ τ R θ ( τ ) P θ ( τ ) \overline{R}_{\theta} = \sum_\tau R_{\theta}(\tau) P_{\theta}(\tau)
R θ = τ ∑ R θ ( τ ) P θ ( τ )
那么,总体的训练目标就是令期望的总奖励最大,即
θ ∗ = arg max θ R ‾ θ \theta^* = \argmax_{\theta} \overline{R}_{\theta}
θ ∗ = θ arg max R θ
可通过梯度下降法求取
∇ R ‾ θ = ∑ τ R θ ( τ ) ⋅ ∇ P θ ( τ ) = ∑ τ R θ ( τ ) ⋅ P θ ( τ ) ⋅ ∇ log P θ ( τ ) = E τ ∼ P θ ( τ ) R θ ( τ ) ⋅ ∇ log P θ ( τ ) ≈ 1 ∣ T ∣ ∑ τ ∈ T R θ ( τ ) ⋅ ∇ log P θ ( τ ) \begin{aligned}
\nabla \overline{R}_{\theta} &= \sum_\tau R_{\theta}(\tau) \cdot \nabla P_{\theta}(\tau) \\
&= \sum_\tau R_{\theta}(\tau) \cdot P_{\theta}(\tau) \cdot \nabla \log P_{\theta}(\tau) \\
&= E_{\tau \sim P_{\theta}(\tau)} R_{\theta}(\tau) \cdot \nabla \log P_{\theta}(\tau) \\
&\approx \frac{1}{|\Tau|} \sum_{\tau \in \Tau} R_{\theta}(\tau) \cdot \nabla \log P_{\theta}(\tau) \\
\end{aligned}
∇ R θ = τ ∑ R θ ( τ ) ⋅ ∇ P θ ( τ ) = τ ∑ R θ ( τ ) ⋅ P θ ( τ ) ⋅ ∇ log P θ ( τ ) = E τ ∼ P θ ( τ ) R θ ( τ ) ⋅ ∇ log P θ ( τ ) ≈ ∣ T ∣ 1 τ ∈ T ∑ R θ ( τ ) ⋅ ∇ log P θ ( τ )
注:∇ f ( x ) = f ( x ) ⋅ ∇ f ( x ) f ( x ) = f ( x ) ⋅ ∇ l o g f ( x ) \nabla f(x) = f(x) \cdot \frac{\nabla f(x)}{f(x)} = f(x) \cdot \nabla log f(x) ∇ f ( x ) = f ( x ) ⋅ f ( x ) ∇ f ( x ) = f ( x ) ⋅ ∇ l o g f ( x )
而根据马尔可夫独立性假设,有
P θ ( τ ) = P ( s 1 ) ⋅ P ( a 1 ∣ s 1 ) P ( s 2 ∣ s 1 , a 1 ) ⋅ P ( a 2 ∣ s 2 ) P ( s 3 ∣ s 2 , a 2 ) ⋯ = P ( s 1 ) ∏ t P ( a t ∣ s t ) P ( s t + 1 ∣ s t , a t ) \begin{aligned}
P_{\theta}(\tau) &= P(s_1) \cdot P(a_1|s_1) P(s_2|s_1, a_1) \cdot P(a_2|s_2) P(s_3|s_2, a_2) \cdots \\
&= P(s_1) \prod_{t} P(a_t|s_t) P(s_{t+1}|s_t, a_t)
\end{aligned}
P θ ( τ ) = P ( s 1 ) ⋅ P ( a 1 ∣ s 1 ) P ( s 2 ∣ s 1 , a 1 ) ⋅ P ( a 2 ∣ s 2 ) P ( s 3 ∣ s 2 , a 2 ) ⋯ = P ( s 1 ) t ∏ P ( a t ∣ s t ) P ( s t + 1 ∣ s t , a t )
则
log P θ ( τ ) = log P ( s 1 ) ‾ + ∑ t log P ( a t ∣ s t ) + log P ( s t + 1 ∣ s t , a t ) ‾ \log P_{\theta}(\tau) = \underline{\log P(s_1)} + \sum_t \log P(a_t|s_t) + \underline{\log P(s_{t+1}|s_t, a_t)}
log P θ ( τ ) = log P ( s 1 ) + t ∑ log P ( a t ∣ s t ) + log P ( s t + 1 ∣ s t , a t )
那么
∇ log P θ ( τ ) = ∑ t ∇ log P ( a t ∣ s t ) \nabla \log P_{\theta}(\tau) = \sum_t \nabla \log P(a_t|s_t)
∇ log P θ ( τ ) = t ∑ ∇ log P ( a t ∣ s t )
代入∇ R ‾ θ \nabla \overline{R}_{\theta} ∇ R θ
∇ R ‾ θ ≈ 1 ∣ T ∣ ∑ τ ∈ T R θ ( τ ) ⋅ ∑ t ∇ log π ( a t ∣ s t ; θ ) ‾ ≈ 1 ∣ T ∣ ∑ τ ∈ T ∑ t r t ⋅ ∇ log π ( a t ∣ s t ; θ ) \begin{aligned}
\nabla \overline{R}_{\theta}
\approx \frac{1}{|\Tau|} \sum_{\tau \in \Tau} R_{\theta}(\tau) \cdot \underline{\sum_t \nabla \log \pi(a_t|s_t; \theta)}
\approx \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} r_t \cdot \nabla \log \pi(a_t|s_t; \theta)
\end{aligned}
∇ R θ ≈ ∣ T ∣ 1 τ ∈ T ∑ R θ ( τ ) ⋅ t ∑ ∇ log π ( a t ∣ s t ; θ ) ≈ ∣ T ∣ 1 τ ∈ T ∑ t ∑ r t ⋅ ∇ log π ( a t ∣ s t ; θ )
因此
{ ∇ R ‾ θ ≈ 1 ∣ T ∣ ∑ τ ∈ T ∑ t r t ⋅ ∇ log π ( a t ∣ s t ; θ ) θ ← θ + η ∇ R ‾ θ \begin{cases}
\nabla \overline{R}_{\theta} &\approx \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} r_t \cdot \nabla \log \pi(a_t|s_t; \theta) \\
\theta &\leftarrow \theta + \eta \nabla \overline{R}_{\theta} \\
\end{cases}
{ ∇ R θ θ ≈ ∣ T ∣ 1 ∑ τ ∈ T ∑ t r t ⋅ ∇ log π ( a t ∣ s t ; θ ) ← θ + η ∇ R θ
相应地,损失函数为
L = 1 ∣ T ∣ ∑ τ ∈ T ∑ t r t ⋅ log π ( a t ∣ s t ; θ ) L = \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} r_t \cdot \log \pi(a_t|s_t; \theta)
L = ∣ T ∣ 1 τ ∈ T ∑ t ∑ r t ⋅ log π ( a t ∣ s t ; θ )
注:形式上与分类任务交叉熵损失类似??
L = 1 ∣ D ∣ ∑ ( x , y ) ∈ D ∑ c y c log p c ( x ) L = \frac{1}{|D|} \sum_{(x, y) \in D} \sum_c y_c \log p_c(x)
L = ∣ D ∣ 1 ( x , y ) ∈ D ∑ c ∑ y c log p c ( x )
优缺点
PG的优点是:
更好的收敛性质
在高维或连续动作空间有效
可以学习随机策略
不会出现策略退化现象
缺点是:
可以收敛到不动点,但往往是局部最优
对策略的评估往往是低效并且高方差的
数据效率和鲁棒性不行。
PG的变体形式
上面的PG是以最大化每步奖励为目标,还可以将式中的奖励r t r_t r t
L ≈ { 1 ∣ T ∣ ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ r t REINFOCEMENT 1 ∣ T ∣ ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ Q ( s t , a t ; θ ) Q Actor-Critic 1 ∣ T ∣ ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ A ( s t , a t ; θ ) Advantage Actor-Critic 1 ∣ T ∣ ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ δ TD Actor-Critic 1 ∣ T ∣ ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ δ e TD( λ )Actor-Critic L \approx \begin{cases}
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \log \pi(a_t|s_t; \theta) \cdot r_t & \text{REINFOCEMENT} \\
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \log \pi(a_t|s_t; \theta) \cdot Q(s_t, a_t; \theta) & \text{Q Actor-Critic} \\
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \log \pi(a_t|s_t; \theta) \cdot A(s_t, a_t; \theta) & \text{Advantage Actor-Critic} \\
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \log \pi(a_t|s_t; \theta) \cdot \delta & \text{TD Actor-Critic} \\
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \log \pi(a_t|s_t; \theta) \cdot \delta e & \text{TD(} \lambda \text{)Actor-Critic} \\
\end{cases}
L ≈ ⎩ ⎨ ⎧ ∣ T ∣ 1 ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ r t ∣ T ∣ 1 ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ Q ( s t , a t ; θ ) ∣ T ∣ 1 ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ A ( s t , a t ; θ ) ∣ T ∣ 1 ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ δ ∣ T ∣ 1 ∑ τ ∈ T ∑ t log π ( a t ∣ s t ; θ ) ⋅ δe REINFOCEMENT Q Actor-Critic Advantage Actor-Critic TD Actor-Critic TD( λ )Actor-Critic
这几种变体是怎么来的呢?以第三种 Advantage Actor-Critic 为例,我们深入讲一讲就能理解其他变体的含义。
变体:Advantage Actor-Critic(Advantage AC)
先对PG进行两项改进:
改进1 :增加一个奖励基准b b b b b b
L ≈ 1 ∣ T ∣ ∑ τ ∈ T ∑ t ( r t − b ) ‾ ⋅ log π ( a t ∣ s t ; θ ) L \approx \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \underline{(r_t - b)} \cdot \log \pi(a_t|s_t; \theta)
L ≈ ∣ T ∣ 1 τ ∈ T ∑ t ∑ ( r t − b ) ⋅ log π ( a t ∣ s t ; θ )
改进2 :上式中每个时间步t t t ( s t , a t ) (s_t, a_t) ( s t , a t ) r t r_t r t 没有考虑这一步采取动作可能带来的全局的、更长远的影响 。所以,可以用奖励的累加,也就是t t t g t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ = ∑ k = 0 N γ k r t + k g_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \cdots = \sum_{k=0}^N \gamma^k r_{t+k} g t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ = ∑ k = 0 N γ k r t + k 0 < γ < 1 0< \gamma < 1 0 < γ < 1
r t → ∑ t ′ ≥ t r t ′ → ∑ t ′ ≥ t γ t ′ − t r t ′ r_t \rightarrow \sum_{t' \ge t} r_{t'} \rightarrow \sum_{t' \ge t} \gamma^{t'-t} r_{t'}
r t → t ′ ≥ t ∑ r t ′ → t ′ ≥ t ∑ γ t ′ − t r t ′
L ≈ 1 ∣ T ∣ ∑ τ ∈ T ∑ t ( ∑ t ′ ≥ t γ t ′ − t r t ′ − b ‾ ) ⋅ log π ( a t ∣ s t ; θ ) L \approx \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} (\underline{\sum_{t' \ge t} \gamma^{t'-t} r_{t'} - b}) \cdot \log \pi(a_t|s_t; \theta)
L ≈ ∣ T ∣ 1 τ ∈ T ∑ t ∑ ( t ′ ≥ t ∑ γ t ′ − t r t ′ − b ) ⋅ log π ( a t ∣ s t ; θ )
回顾一下优势函数的定义,A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) A π ( s , a ) = Q π ( s , a ) − V π ( s ) 可以发现划线部分实际上是简化的优势函数 ,即
{ Q π ( s , a ) = ∑ t ′ ≥ t γ t ′ − t r t ′ V π ( s ) = b ( 常数 ) ⇒ A ( s t , a t ; θ ) = ∑ t ′ ≥ t γ t ′ − t r t ′ − b \begin{cases}
Q^\pi(s, a) &= \sum_{t' \ge t} \gamma^{t'-t} r_{t'} \\
V^\pi(s) &= b (常数)
\end{cases}
\Rightarrow
A(s_t, a_t; \theta) = \sum_{t' \ge t} \gamma^{t'-t} r_{t'} - b
{ Q π ( s , a ) V π ( s ) = ∑ t ′ ≥ t γ t ′ − t r t ′ = b ( 常数 ) ⇒ A ( s t , a t ; θ ) = t ′ ≥ t ∑ γ t ′ − t r t ′ − b
此时就得到了变体Advantage Actor-Critic,优化目标如下。和PG最大化每步奖励不同,这种方法是最大化每步的采取动作的优势。
θ ∗ = arg max θ 1 ∣ T ∣ ∑ τ ∈ T ∑ t A ( s t , a t ; θ ) ⋅ log π ( a t ∣ s t ; θ ) \theta^* = \argmax_{\theta} \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} A(s_t, a_t; \theta) \cdot \log \pi(a_t|s_t; \theta)
θ ∗ = θ arg max ∣ T ∣ 1 τ ∈ T ∑ t ∑ A ( s t , a t ; θ ) ⋅ log π ( a t ∣ s t ; θ )
既然价值函数的最简形式是采取常数项,是不是能将其参数化呢?于是就得到了AC框架,Actor即策略π ( a t ∣ s t ; θ ) \pi(a_t|s_t; \theta) π ( a t ∣ s t ; θ ) 用模型预估当前状态s t s_t s t 。那么如何训练Critic呢?一种方式是把奖励r t r_t r t 实际上环境的奖励r t r_t r t ,那么价值函数的优化目标变成了
ϕ ∗ = arg min ϕ 1 ∣ T ∣ ∑ τ ∈ T ∑ t ( V ( s t ; ϕ ) − r t ) 2 \phi^* = \argmin_{\phi} \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} (V(s_t; \phi) - r_t)^2
ϕ ∗ = ϕ arg min ∣ T ∣ 1 τ ∈ T ∑ t ∑ ( V ( s t ; ϕ ) − r t ) 2
也可以设置其他优化目标,比如A2C 中用Q值计算损失。
例程:CartPole-v1
Policy Gradient的例程,智能体通过控制滑块左右移动来保持杆子处于竖直状态:
环境状态:由滑块位置x x x x ′ x' x ′ θ \theta θ θ ′ \theta' θ ′
动作空间:包含向左、向右两个可选动作。
奖励函数:每个时间步,如果杆的角度在±12°范围内,并且小车没有超出±2.4单位的轨道边界,则给予奖励+1;如果杆超出角度范围或小车超出边界,环境将结束,且不再给予奖励。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 import osimport gymimport numpy as npfrom copy import deepcopyfrom collections import dequeimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.distributions import Categoricalenv = gym.make('CartPole-v1' ) env = env.unwrapped state_dims = env.observation_space.shape[0 ] n_actions = env.action_space.n device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" ) class Net (nn.Module): def __init__ (self ): super ().__init__() self .layers = nn.Sequential( nn.Linear(state_dims, 32 ), nn.ReLU(inplace=True ), nn.Linear(32 , 32 ), nn.ReLU(inplace=True ), nn.Linear(32 , n_actions), nn.Softmax(dim=-1 ), ) def forward (self, state ): pi = self .layers(state) return pi class PG (): def __init__ ( self, gamma=0.9 , lr=5e-4 , weight_decay=0.0 , ): self .gamma = gamma self .buffer = [] self .model = Net() self .model.to(device) self .optimizer = torch.optim.Adam(self .model.parameters(), lr=lr, weight_decay=weight_decay) @torch.no_grad() def choose_action (self, state ): state = torch.from_numpy(state).float ().unsqueeze(0 ).to(device) pi = self .model(state) dist = torch.distributions.Categorical(pi) action = dist.sample().item() return action def store_experience (self, experience ): self .buffer.append(experience) def update (self ): get_tensor = lambda x: torch.tensor([b[x] for b in self .buffer]).to(device) states = get_tensor(0 ).float () actions = get_tensor(1 ).long() rewards = get_tensor(2 ).float () for t in reversed (range (0 , rewards.size(0 ) - 1 )): rewards[t] = rewards[t] + self .gamma * rewards[t + 1 ] rewards = (rewards - rewards.mean()) / rewards.std() pi = self .model(states) log_prob = torch.sum (pi.log() * F.one_hot(actions), dim=1 ) loss = - (log_prob * rewards).mean() self .optimizer.zero_grad() loss.backward() self .optimizer.step() del self .buffer[:] return loss.item() def train (agent, num_episodes=2000 , render=False ): step = 0 for i in range (num_episodes): total_rewards = 0 done = False state, _ = env.reset() while not done: step += 1 if render: env.render() action = agent.choose_action(state) next_state, reward, done, truncated, info = env.step(action) x, x_dot, theta, theta_dot = next_state r1 = (env.x_threshold - abs (x)) / env.x_threshold - 0.8 r2 = (env.theta_threshold_radians - abs (theta)) / env.theta_threshold_radians - 0.5 r3 = 3 * r1 + r2 agent.store_experience((state, action, r3, next_state, done)) state = next_state total_rewards += reward loss = agent.update() if i % 50 == 0 : print ('episode:{} reward:{}' .format (i, total_rewards)) def test (agent, num_episodes=10 , render=False ): env = gym.make('CartPole-v1' , render_mode="human" if render else None ) step = 0 eval_rewards = [] for i in range (num_episodes): total_rewards = 0 done = False state, _ = env.reset() while not done: step += 1 if render: env.render() action = agent.choose_action(state) next_state, reward, done, truncated, info = env.step(action) state = next_state total_rewards += reward eval_rewards.append(total_rewards) return sum (eval_rewards) / len (eval_rewards) if __name__ == "__main__" : agent = PG() train(agent, render=False ) test(agent, render=True )
TRPO
强化学习包含智能体在环境中的探索和参数更新两个主要步骤,以最大化回报为强化学习目标,有
θ ∗ = arg max θ ∑ t γ t r t ( θ ) = arg max θ g ( τ ; θ ) \theta^* = \argmax_\theta \sum_t \gamma^t r_t(\theta) = \argmax_\theta g(\tau; \theta)
θ ∗ = θ arg max t ∑ γ t r t ( θ ) = θ arg max g ( τ ; θ )
但如果学习率α \alpha α θ ~ \tilde{\theta} θ ~ θ \theta θ θ ~ \tilde{\theta} θ ~
TRPO(Trust Region Policy Optimization )就是为了解决如何选择一个合适的更新策略,或是如何选择一个合适的步长,使得更新过后的策略π ( a ∣ s ; θ ~ ) \pi(a|s; \tilde{\theta}) π ( a ∣ s ; θ ~ ) π ( a ∣ s ; θ ) \pi(a|s; \theta) π ( a ∣ s ; θ ) 。
方法推导
在策略π ( a t ∣ s t ; θ ) \pi(a_t|s_t;\theta) π ( a t ∣ s t ; θ ) π ( a t ∣ s t ; θ ~ ) \pi(a_t|s_t;\tilde{\theta}) π ( a t ∣ s t ; θ ~ )
g ( θ ) = E τ ∼ P ( τ ∣ θ ) G ( τ ; θ ) g ( θ ~ ) = E τ ∼ P ( τ ∣ θ ~ ) G ( τ ; θ ~ ) \begin{aligned}
g(\theta) &= E_{\tau \sim P(\tau|\theta)} G(\tau; \theta) \\
g(\tilde{\theta}) &= E_{\tau \sim P(\tau|\tilde{\theta})} G(\tau; \tilde{\theta}) \\
\end{aligned}
g ( θ ) g ( θ ~ ) = E τ ∼ P ( τ ∣ θ ) G ( τ ; θ ) = E τ ∼ P ( τ ∣ θ ~ ) G ( τ ; θ ~ )
那么就有
g ( θ ~ ) = g ( θ ) + E τ ∼ P ( τ ∣ θ ~ ) ∑ t γ t A ( s t , a t ; θ ) \begin{aligned}
g(\tilde{\theta})
& = g(\theta) + E_{\tau \sim P(\tau|\tilde{\theta})} \sum_t \gamma^t A (s_t, a_t; \theta) \\
\end{aligned}
g ( θ ~ ) = g ( θ ) + E τ ∼ P ( τ ∣ θ ~ ) t ∑ γ t A ( s t , a t ; θ )
目标也就是使g ( θ ~ ) ≥ g ( θ ) g(\tilde{\theta}) \ge g(\theta) g ( θ ~ ) ≥ g ( θ ) ,定义
ρ ( s ; θ ) = ∑ t = 0 ∞ γ t P ( s ∣ θ ) \rho(s; \theta) = \sum_{t=0}^\infty \gamma^t P(s | \theta)
ρ ( s ; θ ) = t = 0 ∑ ∞ γ t P ( s ∣ θ )
那么
g ( θ ~ ) = g ( θ ) + E τ ∼ P ( τ ∣ θ ~ ) ∑ t γ t A ( s t , a t ; θ ) = g ( θ ) + ∑ t ( ∑ s P ( s ∣ θ ~ ) ( ∑ a π ( a ∣ s ; θ ~ ) ⋅ γ t A ( s , a ; θ ) ) ) = g ( θ ) + ∑ s ∑ t γ t ( P ( s ∣ θ ~ ) ∑ a π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) ) = g ( θ ) + ∑ s ( ρ ( s ; θ ~ ) ∑ a π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) ) \begin{aligned}
g(\tilde{\theta})
& = g(\theta) + E_{\tau \sim P(\tau | \tilde{\theta})} \sum_t \gamma^t A (s_t, a_t; \theta) \\
& = g(\theta) + \sum_t \left(
\sum_s P(s | \tilde{\theta}) \left(
\sum_a \pi(a|s;\tilde{\theta})
\cdot \gamma^t A (s, a; \theta)
\right)
\right) \\
& = g(\theta) + \sum_s \sum_t \gamma^t \left(
P(s | \tilde{\theta}) \sum_a \pi(a|s;\tilde{\theta}) A (s, a; \theta)
\right) \\
& = g(\theta) + \sum_s \left(
\rho(s; \tilde{\theta}) \sum_a \pi(a|s;\tilde{\theta}) A (s, a; \theta)
\right) \\
\end{aligned}
g ( θ ~ ) = g ( θ ) + E τ ∼ P ( τ ∣ θ ~ ) t ∑ γ t A ( s t , a t ; θ ) = g ( θ ) + t ∑ ( s ∑ P ( s ∣ θ ~ ) ( a ∑ π ( a ∣ s ; θ ~ ) ⋅ γ t A ( s , a ; θ ) ) ) = g ( θ ) + s ∑ t ∑ γ t ( P ( s ∣ θ ~ ) a ∑ π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) ) = g ( θ ) + s ∑ ( ρ ( s ; θ ~ ) a ∑ π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) )
上式中ρ ( s ; θ ~ ) \rho(s; \tilde{\theta}) ρ ( s ; θ ~ ) θ ~ \tilde{\theta} θ ~ θ ~ \tilde{\theta} θ ~ 替代函数 L θ ( θ ~ ) L^{\theta}(\tilde{\theta}) L θ ( θ ~ )
L θ ( θ ~ ) = g ( θ ) + ∑ s ( ρ ( s ; θ ) ∑ a π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) ) L^{\theta}(\tilde{\theta})
= g(\theta) + \sum_s \left(
\rho(s; \theta) \sum_a \pi(a|s; \tilde{\theta}) A (s, a; \theta)
\right)
L θ ( θ ~ ) = g ( θ ) + s ∑ ( ρ ( s ; θ ) a ∑ π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) )
该函数与g ( θ ~ ) g(\tilde{\theta}) g ( θ ~ ) θ \theta θ
{ L θ ( θ ) = g ( θ ) ∇ L θ ( θ ) = ∇ g ( θ ) \begin{cases}
L^{\theta}(\theta) &= g(\theta) \\
\nabla L^{\theta}(\theta) &= \nabla g(\theta) \\
\end{cases}
{ L θ ( θ ) ∇ L θ ( θ ) = g ( θ ) = ∇ g ( θ )
一阶近似,是泰勒公式中的一种近似方法,具体指的是在x x x f ( x ) = x − 1 f(x)=x-1 f ( x ) = x − 1 g ( x ) = ln x g(x)=\ln x g ( x ) = ln x x = 1 x=1 x = 1 f ( 1 ) = g ( 1 ) = 0 , f ′ ( 1 ) = g ′ ( 1 ) = 1 f(1)=g(1)=0, f'(1)=g'(1)=1 f ( 1 ) = g ( 1 ) = 0 , f ′ ( 1 ) = g ′ ( 1 ) = 1
可以通过优化L θ ( θ ~ ) L^{\theta}(\tilde{\theta}) L θ ( θ ~ ) g ( θ ~ ) g(\tilde{\theta}) g ( θ ~ )
θ ~ ∗ = arg max θ ~ L θ ( θ ~ ) \tilde{\theta}^* = \argmax_{\tilde{\theta}} L^{\theta}(\tilde{\theta})
θ ~ ∗ = θ ~ arg max L θ ( θ ~ )
但是注意,该参数不能作为更新后的参数θ ~ \tilde{\theta} θ ~
θ ~ ∗ \tilde{\theta}^* θ ~ ∗ θ \theta θ θ ~ ∗ \tilde{\theta}^* θ ~ ∗ θ \theta θ L θ ( θ ~ ∗ ) ≥ L θ ( θ ) L^{\theta}(\tilde{\theta}^*) \ge L^{\theta}(\theta) L θ ( θ ~ ∗ ) ≥ L θ ( θ ) g ( θ ~ ∗ ) ≥ g ( θ ) g(\tilde{\theta}^*) \ge g(\theta) g ( θ ~ ∗ ) ≥ g ( θ )
因此,需要将θ ~ ∗ \tilde{\theta}^* θ ~ ∗ θ \theta θ TRPO算法优化目标
θ ~ = arg max θ ~ L θ ( θ ~ ) s.t. KL ( π ( a ∣ s ; θ ) , π ( a ∣ s ; θ ~ ) ) ≤ δ \begin{aligned}
\tilde{\theta} &= \argmax_{\tilde{\theta}} L^{\theta}(\tilde{\theta}) \\
\text{s.t.} &\quad \text{KL} \left( \pi(a|s; \theta),\pi(a|s; \tilde{\theta}) \right) \leq \delta
\end{aligned}
θ ~ s.t. = θ ~ arg max L θ ( θ ~ ) KL ( π ( a ∣ s ; θ ) , π ( a ∣ s ; θ ~ ) ) ≤ δ
也就是在以θ \theta θ δ \delta δ θ ~ \tilde{\theta} θ ~ L θ ( θ ~ ) L^{\theta}(\tilde{\theta}) L θ ( θ ~ ) π ( a ∣ s ; θ ~ ) \pi(a|s; \tilde{\theta}) π ( a ∣ s ; θ ~ ) 但更新前无法基于未知的π \pi π ,也就是先基于π ( a ∣ s ; θ ) \pi(a|s; \theta) π ( a ∣ s ; θ )
L θ ( θ ~ ) = g ( θ ) + ∑ s ρ ( s ; θ ) ∑ a π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) = g ( θ ) + ∑ s ρ ( s ; θ ) ∑ a π ( a ∣ s ; θ ) ( π ( a ∣ s ; θ ~ ) π ( a ∣ s ; θ ) A ( s , a ; θ ) ) \begin{aligned}
L^{\theta}(\tilde{\theta})
&= g(\theta) + \sum_s \rho(s; \theta) \sum_a \pi(a|s;\tilde{\theta}) A(s, a; \theta) \\
&= g(\theta) + \sum_s \rho(s; \theta) \sum_a \pi(a|s; \theta) \left(
\frac{\pi(a|s;\tilde{\theta})}{\pi(a|s; \theta)} A(s, a; \theta)
\right) \\
\end{aligned}
L θ ( θ ~ ) = g ( θ ) + s ∑ ρ ( s ; θ ) a ∑ π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) = g ( θ ) + s ∑ ρ ( s ; θ ) a ∑ π ( a ∣ s ; θ ) ( π ( a ∣ s ; θ ) π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) )
重要性采样(Importance Sampling),假定概率分布p ( x ) p(x) p ( x ) f ( x ) f(x) f ( x ) E x ∼ p ( x ) f ( x ) E_{x \sim p(x)} f(x) E x ∼ p ( x ) f ( x ) N N N
E x ∼ p ( x ) f ( x ) = ∫ p ( x ) f ( x ) d x ≈ 1 N ∑ x = 1 N f ( x i ) E_{x \sim p(x)} f(x) = \int p(x) f(x) dx \approx \frac{1}{N} \sum_{x=1}^N f(x_i)
E x ∼ p ( x ) f ( x ) = ∫ p ( x ) f ( x ) d x ≈ N 1 x = 1 ∑ N f ( x i )
问题就在于实际问题中:1) 很难确定p ( x ) p(x) p ( x ) p ( x ) p(x) p ( x ) x i x_i x i p ( x ) p(x) p ( x ) [ a , b ] [a, b] [ a , b ] f ( x ) f(x) f ( x ) ∫ a b f ( x ) d x = b − a N ∑ i = 1 N f ( x i ) \int_a^b f(x) dx = \frac{b - a}{N} \sum_{i=1}^N f(x_i) ∫ a b f ( x ) d x = N b − a ∑ i = 1 N f ( x i ) f ( x ) f(x) f ( x )
这种情况下就需要用重要性采样解决,具体地,引入另一个容易采样的分布q ( x ) q(x) q ( x )
E x ∼ p ( x ) f ( x ) = ∫ p ( x ) f ( x ) d x = ∫ q ( x ) p ( x ) q ( x ) f ( x ) d x = E x ∼ q ( x ) p ( x ) q ( x ) f ( x ) ≈ 1 N ∑ x = 1 N p ( x i ) q ( x i ) f ( x i ) ‾ E_{x \sim p(x)} f(x)
= \int p(x) f(x) dx
= \int q(x) \frac{p(x)}{q(x)} f(x) dx
= \underline{
E_{x \sim q(x)} \frac{p(x)}{q(x)} f(x)
\approx \frac{1}{N} \sum_{x=1}^N \frac{p(x_i)}{q(x_i)} f(x_i)
}
E x ∼ p ( x ) f ( x ) = ∫ p ( x ) f ( x ) d x = ∫ q ( x ) q ( x ) p ( x ) f ( x ) d x = E x ∼ q ( x ) q ( x ) p ( x ) f ( x ) ≈ N 1 x = 1 ∑ N q ( x i ) p ( x i ) f ( x i )
式中p ( x i ) q ( x i ) \frac{p(x_i)}{q(x_i)} q ( x i ) p ( x i ) p ( x ) p(x) p ( x ) q ( x ) q(x) q ( x )
每一步的策略梯度更新对应
θ ~ = arg max θ ~ E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) π ( a ∣ s ; θ ~ ) π ( a ∣ s ; θ ) A ( s , a ; θ ) s.t. KL ( π ( a ∣ s ; θ ) , π ( a ∣ s ; θ ~ ) ) ≤ δ \begin{aligned}
\tilde{\theta} &= \argmax_{\tilde{\theta}} E_{s \sim \rho(s; \theta), a \sim \pi(a|s; \theta)}
\frac{\pi(a|s;\tilde{\theta})}{\pi(a|s; \theta)} A(s, a; \theta) \\
\text{s.t.} &\quad \text{KL} \left( \pi(a|s; \theta),\pi(a|s; \tilde{\theta}) \right) \leq \delta
\end{aligned}
θ ~ s.t. = θ ~ arg max E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) π ( a ∣ s ; θ ) π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) KL ( π ( a ∣ s ; θ ) , π ( a ∣ s ; θ ~ ) ) ≤ δ
对比 Advantage Actor-Critic 的优化目标
θ ∗ = arg max θ E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) log π ( a ∣ s ; θ ) A ( s , a ; θ ) \theta^* = \argmax_{\theta} E_{s \sim \rho(s; \theta), a \sim \pi(a|s; \theta)} \log \pi(a|s; \theta) A(s, a; \theta)
θ ∗ = θ arg max E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) log π ( a ∣ s ; θ ) A ( s , a ; θ )
PPO(DeepMind)
TRPO算法引入了KL散度来保证分布相近,需要解决带约束的优化问题。PPO(Proximal Policy Optimization Algorithms)算法是对它的简化。既然是最小化KL散度,那么直接把它也作为目标函数的一部分,得到
θ ~ = arg max θ ~ E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) ( π ( a ∣ s ; θ ~ ) π ( a ∣ s ; θ ) A ( s , a ; θ ) − β KL ( π ( a ∣ s ; θ ) , π ( a ∣ s ; θ ~ ) ) ) \begin{aligned}
\tilde{\theta} &= \argmax_{\tilde{\theta}}
E_{s \sim \rho(s; \theta), a \sim \pi(a|s; \theta)} \left(
\frac{\pi(a|s;\tilde{\theta})}{\pi(a|s; \theta)} A(s, a; \theta)
- \beta \text{KL} \left(
\pi(a|s; \theta),\pi(a|s; \tilde{\theta})
\right)
\right)
\end{aligned}
θ ~ = θ ~ arg max E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) ( π ( a ∣ s ; θ ) π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) − β KL ( π ( a ∣ s ; θ ) , π ( a ∣ s ; θ ~ ) ) )
其中β \beta β KL > KL max \text{KL} > \text{KL}_{\max} KL > KL m a x β \beta β KL < KL min \text{KL} < \text{KL}_{\min} KL < KL m i n β \beta β
PPO2(OpenAI)
另一种简化方式,采取截断来使两分布的比值在( 1 − ϵ , 1 + ϵ ) (1 - \epsilon, 1 + \epsilon) ( 1 − ϵ , 1 + ϵ )
θ ~ = arg max θ ~ E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) min ( π ( a ∣ s ; θ ~ ) π ( a ∣ s ; θ ) A ( s , a ; θ ) , clip ( π ( a ∣ s ; θ ~ ) π ( a ∣ s ; θ ) , 1 − ϵ , 1 + ϵ ) A ( s , a ; θ ) ) \begin{aligned}
\tilde{\theta} &= \argmax_{\tilde{\theta}}
E_{s \sim \rho(s; \theta), a \sim \pi(a|s; \theta)} \min \left(
\frac{\pi(a|s;\tilde{\theta})}{\pi(a|s; \theta)} A(s, a; \theta),
\text{clip} (
\frac{\pi(a|s;\tilde{\theta})}{\pi(a|s; \theta)}, 1 - \epsilon, 1 + \epsilon
) A(s, a; \theta)
\right)
\end{aligned}
θ ~ = θ ~ arg max E s ∼ ρ ( s ; θ ) , a ∼ π ( a ∣ s ; θ ) min ( π ( a ∣ s ; θ ) π ( a ∣ s ; θ ~ ) A ( s , a ; θ ) , clip ( π ( a ∣ s ; θ ) π ( a ∣ s ; θ ~ ) , 1 − ϵ , 1 + ϵ ) A ( s , a ; θ ) )
例程
智能体通过控制左右旋转力度来保持杆子处于竖直状态(Actor-Critic 框架),使用Pendulum-v1环境,这是一个倒立摆环境,
环境状态:三维,由摆杆的角度θ ∈ [ − π , π ] \theta \in [-\pi, \pi] θ ∈ [ − π , π ] θ ′ \theta' θ ′ cos ( θ ) \cos(\theta) cos ( θ ) sin ( θ ) \sin(\theta) sin ( θ )
动作空间:施加在摆杆上的扭矩torque \text{torque} torque [ − 2 , 2 ] N ⋅ m [-2, 2] N \cdot m [ − 2 , 2 ] N ⋅ m
奖励函数:r = − ( θ 2 + 0.1 θ ′ 2 + 0.001 torque 2 ) r = - (\theta^2 + 0.1 \theta'^2 + 0.001 \text{torque}^2) r = − ( θ 2 + 0.1 θ ′2 + 0.001 torque 2 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 import osimport randomimport argparsefrom collections import namedtupleimport gymimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.distributions import Normalfrom torch.utils.data.sampler import BatchSampler, SubsetRandomSamplerparser = argparse.ArgumentParser(description='Solve the Pendulum with PPO' ) parser.add_argument('--gamma' , type =float , default=0.9 , metavar='G' , help ='discount factor (default: 0.9)' ) parser.add_argument('--seed' , type =int , default=0 , metavar='N' , help ='random seed (default: 0)' ) parser.add_argument('--render' , action='store_true' , default=False , help ='render the environment' ) parser.add_argument('--log-interval' , type =int , default=10 , metavar='N' , help ='interval between training status logs (default: 10)' ) args = parser.parse_args() env = gym.make('Pendulum-v1' , render_mode='human' if args.render else None ).unwrapped state_dims = env.observation_space.shape[0 ] num_action = env.action_space.shape[0 ] torch.manual_seed(args.seed) random.seed(args.seed) Experience = namedtuple('Experience' , ['state' , 'action' , 'a_log_prob' , 'reward' , 'next_state' ]) TrainRecord = namedtuple('TrainRecord' , ['episode' , 'reward' ]) class Actor (nn.Module): def __init__ (self ): super (Actor, self ).__init__() self .fc = nn.Linear(state_dims, 100 ) self .mu_head = nn.Linear(100 , 1 ) self .sigma_head = nn.Linear(100 , 1 ) def forward (self, x ): x = F.tanh(self .fc(x)) mu = 2.0 * F.tanh(self .mu_head(x)) sigma = F.softplus(self .sigma_head(x)) return (mu, sigma) class Critic (nn.Module): def __init__ (self ): super (Critic, self ).__init__() self .fc1 = nn.Linear(state_dims, 64 ) self .fc2 = nn.Linear(64 , 8 ) self .state_value = nn.Linear(8 , 1 ) def forward (self, x ): x = F.leaky_relu(self .fc1(x)) x = F.relu(self .fc2(x)) value = self .state_value(x) return value class PPO2 (): clip_epsilon = 0.2 max_grad_norm = 0.5 ppo_epoch = 10 buffer_capacity, batch_size = 1000 , 32 def __init__ (self ): super (PPO2, self ).__init__() self .actor_net = Actor().float () self .critic_net = Critic().float () self .buffer = [] self .counter = 0 self .training_step = 0 self .actor_optimizer = optim.Adam(self .actor_net.parameters(), lr=1e-4 ) self .critic_net_optimizer = optim.Adam(self .critic_net.parameters(), lr=3e-4 ) def save_param (self ): torch.save(self .actor_net.state_dict(), 'ppo2_actor_params.pkl' ) torch.save(self .critic_net.state_dict(), 'ppo2_critic_params.pkl' ) def load_param (self ): self .actor_net.load_state_dict(torch.load('ppo2_actor_params.pkl' )) self .critic_net.load_state_dict(torch.load('ppo2_critic_params.pkl' )) @torch.no_grad() def choose_action (self, state ): state = torch.from_numpy(state).float ().unsqueeze(0 ) mu, sigma = self .actor_net(state) dist = Normal(mu, sigma) action = dist.sample() action = action.clamp(-2 , 2 ) action_log_prob = dist.log_prob(action).item() return action.item(), action_log_prob @torch.no_grad() def get_value (self, state ): state = torch.from_numpy(state) value = self .critic_net(state).item() return value def store_experience (self, experience ): self .buffer.append(experience) self .counter += 1 def should_update (self ): return self .counter % self .buffer_capacity == 0 def update (self ): self .training_step += 1 state = torch.tensor([t.state for t in self .buffer], dtype=torch.float ) action = torch.tensor([t.action for t in self .buffer], dtype=torch.float ).view(-1 , 1 ) action_log_prob_old = torch.tensor( [t.a_log_prob for t in self .buffer], dtype=torch.float ).view(-1 , 1 ) reward = torch.tensor([t.reward for t in self .buffer], dtype=torch.float ).view(-1 , 1 ) next_state = torch.tensor([t.next_state for t in self .buffer], dtype=torch.float ) del self .buffer[:] with torch.no_grad(): reward = (reward + 8 ) / 8 reward = (reward - reward.mean()) / (reward.std() + 1e-5 ) V_ = self .critic_net(next_state) Q = reward + args.gamma * V_ V = self .critic_net(state) A = Q - V for _ in range (self .ppo_epoch): for index in BatchSampler(SubsetRandomSampler(range (self .buffer_capacity)), self .batch_size, False ): mu, sigma = self .actor_net(state[index]) dist = Normal(mu, sigma) action_log_prob = dist.log_prob(action[index]) ratio = torch.exp( action_log_prob - action_log_prob_old[index] ) action_loss = - torch.min ( ratio * A[index], torch.clamp( ratio, 1 - self .clip_epsilon, 1 + self .clip_epsilon ) * A[index], ).mean() self .actor_optimizer.zero_grad() action_loss.backward() nn.utils.clip_grad_norm_(self .actor_net.parameters(), self .max_grad_norm) self .actor_optimizer.step() target_v = reward[index] + args.gamma * V_[index] value_loss = F.smooth_l1_loss(self .critic_net(state[index]), target_v) self .critic_net_optimizer.zero_grad() value_loss.backward() nn.utils.clip_grad_norm_(self .critic_net.parameters(), self .max_grad_norm) self .critic_net_optimizer.step() def main (is_training ): agent = PPO2() if not is_training: agent.load_param() args.render = True training_records = [] running_reward = -1000 for i_epoch in range (1000 ): score = 0 state, _ = env.reset() if args.render: env.render() for t in range (200 ): action, action_log_prob = agent.choose_action(state) next_state, reward, done, truncated, info = env.step([action]) if args.render: env.render() if is_training: trans = Experience(state, action, action_log_prob, reward, next_state) agent.store_experience(trans) if agent.should_update(): agent.update() score += reward state = next_state running_reward = running_reward * 0.9 + score * 0.1 training_records.append(TrainRecord(i_epoch, running_reward)) if i_epoch % 10 == 0 : print ("Epoch {}, Moving average score is: {:.2f} " .format (i_epoch, running_reward)) if running_reward > -200 : print ("Solved! Moving average score is now {}!" .format (running_reward)) env.close() agent.save_param() break if __name__ == '__main__' : main(is_training=True ) main(is_training=False )
Part 4: 从Actor-Critic到A2C/A3C
PG一节已经介绍了从 PG 得到变体 Advantage Actor-Critic 的演变过程,AC框架中的 Actor 就是智能体π ( a t ∣ s t ; θ ) \pi(a_t|s_t; \theta) π ( a t ∣ s t ; θ ) 用模型预估当前状态s s s 。这一节更多的是 AC 算法的定义,以及介绍两种改进算法 A2C 和 A3C。
AC: Actor-Critic
policy-based可以在连续空间内选择合适动作,而这对value-based方法来说搜索空间过大;但是policy-based基于回合更新,学习效率低,通过value-based作为critic可以实现单步更新。因此,Actor-Critic算法结合了两类方法,包含Actor、Critic两部分:
Actor:policy-based,在连续动作空间内选择合适的动作,即策略函数π ( a ∣ s ) \pi(a|s) π ( a ∣ s )
Critic:value-based,评估actor产生的动作,如状态价值函数V ( s ) V(s) V ( s )
Actor的更新参数的目标是让Critic的输出值越大越好。当确定状态s s s a a a r r r
在基于蒙特卡洛的策略梯度REINFORCEMENT中,参数更新公式为
θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ r t \theta \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot r_t
θ ← θ + η ∣ T ∣ 1 τ ∈ T ∑ t ∑ ∇ log π ( a t ∣ s t ; θ ) ⋅ r t
其中r t r_t r t
θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ Q ( s t , a t ; θ ) \theta \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot Q(s_t, a_t; \theta)
θ ← θ + η ∣ T ∣ 1 τ ∈ T ∑ t ∑ ∇ log π ( a t ∣ s t ; θ ) ⋅ Q ( s t , a t ; θ )
其中,Critic模型Q ( s t , a t ; θ ) Q(s_t, a_t; \theta) Q ( s t , a t ; θ )
θ ← θ + η ∇ ∣ ∣ r t + max a ′ Q ( s t + 1 , a ′ ; θ ) − Q ( s t , a t ; θ ) ∣ ∣ 2 2 \theta \leftarrow \theta + \eta \nabla
||r_t + \max_{a'} Q(s_{t+1}, a'; \theta) - Q(s_t, a_t; \theta)||_2^2
θ ← θ + η ∇∣∣ r t + a ′ max Q ( s t + 1 , a ′ ; θ ) − Q ( s t , a t ; θ ) ∣ ∣ 2 2
另外,广义的Actor-Critic可以有以下几种
{ θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ V π ( s t ) 基于状态价值 θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ Q ( s t , a t ; θ ) 基于动作价值 θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ δ ( t ) 基于 T D 误差 θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ A ( s t , a t ; θ ) 基于优势函数 θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ δ ( t ) E ( t ) 基于 T D ( λ ) 误差 \begin{cases}
\theta & \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot V^{\pi}(s_{t})
& 基于状态价值 \\
\theta & \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot Q(s_t, a_t; \theta)
& 基于动作价值 \\
\theta & \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot \delta(t)
& 基于TD误差 \\
\theta & \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot A(s_t, a_t; \theta)
& 基于优势函数 \\
\theta & \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta) \cdot \delta(t) E(t)
& 基于TD(\lambda)误差 \\
\end{cases}
⎩ ⎨ ⎧ θ θ θ θ θ ← θ + η ∣ T ∣ 1 ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ V π ( s t ) ← θ + η ∣ T ∣ 1 ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ Q ( s t , a t ; θ ) ← θ + η ∣ T ∣ 1 ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ δ ( t ) ← θ + η ∣ T ∣ 1 ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ A ( s t , a t ; θ ) ← θ + η ∣ T ∣ 1 ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ δ ( t ) E ( t ) 基于状态价值 基于动作价值 基于 T D 误差 基于优势函数 基于 T D ( λ ) 误差
A2C: Advantage Actor-Critic
A2C的出现是为了解决AC的高方差问题。 A2C与AC的不同之处在于,给Q值增加了一个baseline,我们用Q值减去这个baseline来判断当前逻辑的好坏,这个baseline通常由V π ( s t ) V^{\pi}(s_t) V π ( s t )
θ ← θ + η 1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ ( Q ( s t , a t ; θ ) − V π ( s t ) ) \theta \leftarrow \theta + \eta
\frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t}
\nabla \log \pi(a_t|s_t; \theta) \cdot
\left(
Q(s_t, a_t; \theta) - V^{\pi}(s_t)
\right)
θ ← θ + η ∣ T ∣ 1 τ ∈ T ∑ t ∑ ∇ log π ( a t ∣ s t ; θ ) ⋅ ( Q ( s t , a t ; θ ) − V π ( s t ) )
因此,既需要学习一个Actor来决策选什么动作,又需要Critic来评估V值和Q值,但是同时估计V值和Q值是很复杂的。执行一个动作的下一回合必定更新到s t + 1 s_{t+1} s t + 1 r t r_t r t
{ Q π ( s , a ) = r ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) V π ( s ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ] ( 贝尔曼方程 ) \begin{cases}
Q^\pi(s, a) &= r(s, a) + \gamma \sum_{s' \in S} P(s'|s, a) V^\pi(s') \\
V^{\pi}(s) &= E_\pi[r_t + \gamma V^{\pi}(s_{t+1}) | S=s_t] (贝尔曼方程) \\
\end{cases}
{ Q π ( s , a ) V π ( s ) = r ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) V π ( s ′ ) = E π [ r t + γ V π ( s t + 1 ) ∣ S = s t ] ( 贝尔曼方程 )
我们可以用r t + γ V π ( s t + 1 ) r_t + \gamma V^{\pi}(s_{t+1}) r t + γ V π ( s t + 1 ) Q π ( s , a ) Q^\pi(s, a) Q π ( s , a )
δ ( t ) = r t + γ V π ( s t + 1 ) ‾ t a r g e t V − V π ( s t ) \delta(t) = \underline{r_t + \gamma V^{\pi}(s_{t+1})}_{target V} - V^{\pi}(s_{t})
δ ( t ) = r t + γ V π ( s t + 1 ) t a r g e t V − V π ( s t )
也就是
1 ∣ T ∣ ∑ τ ∈ T ∑ t ∇ log π ( a t ∣ s t ; θ ) ⋅ ( r t + γ V π ( s t + 1 ) − V π ( s t ) ) \frac{1}{|\Tau|} \sum_{\tau \in \Tau} \sum_{t} \nabla \log \pi(a_t|s_t; \theta)
\cdot \left(
r_t + \gamma V^{\pi}(s_{t+1}) - V^{\pi}(s_{t})
\right)
∣ T ∣ 1 τ ∈ T ∑ t ∑ ∇ log π ( a t ∣ s t ; θ ) ⋅ ( r t + γ V π ( s t + 1 ) − V π ( s t ) )
其中,Critic模型V π ( s ) V^{\pi}(s) V π ( s )
θ ← θ + η ∇ ∣ ∣ r t + γ V π ( s t + 1 ) ‾ − V π ( s t ) ∣ ∣ 2 2 \theta \leftarrow \theta + \eta \nabla ||\underline{r_t + \gamma V^{\pi}(s_{t+1})} - V^{\pi}(s_{t})||_2^2
θ ← θ + η ∇∣∣ r t + γ V π ( s t + 1 ) − V π ( s t ) ∣ ∣ 2 2
A3C: Asynchronous Advantage Actor Critic
A3C算法完全使用了Actor-Critic框架,并且引入了异步训练的思想(异步是指数据并非同时产生),在提升性能的同时也大大加快了训练速度。A
Agent与环境的每次实时交互都需要耗费很多的内存和计算力;
经验回放机制要求Agent采用离策略(off-policy)方法来进行学习,而off-policy方法只能基于旧策略生成的数据进行更新;
3C算法为了提升训练速度采用异步训练的思想,利用多个线程。每个线程相当于一个智能体在随机探索,多个智能体共同探索,并行计算策略梯度,对参数进行更新。或者说同时启动多个训练环境,同时进行采样,并直接使用采集的样本进行训练,这里的异步得到数据,相比DQN算法,A3C算法不需要使用经验池来存储历史样本并随机抽取训练来打乱数据相关性,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度。与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练。
参考资料